Domine a Integração de LLMs: Um Guia Técnico com LangChain e OpenAI
A ascensão dos LLMs (Large Language Models), popularizada pelo ChatGPT API da OpenAI, transformou a maneira como interagimos com a inteligência artificial. No entanto, construir aplicações que realmente agreguem valor exige mais do que apenas chamar uma API; requer orquestração. É aqui que frameworks como o LangChain se tornam indispensáveis. Trabalhando diariamente com automação na Host You Secure, percebi que a chave para o sucesso reside em estruturar essas interações de forma modular e escalável. Este artigo detalha como você pode aplicar esses conceitos na prática.
A pergunta central que muitos clientes nos trazem é: Como eu transformo o poder bruto de um LLM em um serviço consistente e produtivo? A resposta, baseada em minha experiência, é através de um bom design de arquitetura, focando em componentes como LangChain, que gerencia a complexidade das chamadas e do estado.
Entendendo os Pilares: LLMs, OpenAI e a Necessidade de Orquestração
Para começar, precisamos solidificar o vocabulário. Um LLM é um modelo treinado em vastas quantidades de dados textuais, capaz de gerar, resumir e entender linguagem natural. A OpenAI é, atualmente, o principal provedor de acesso via API a modelos de ponta como o GPT-4.
O Gargalo da Simples Chamada de API
Na sua forma mais básica, usar o ChatGPT API é uma requisição HTTP para um endpoint específico. Isso funciona para tarefas simples, como tradução ou classificação de texto. No entanto, aplicações reais geralmente exigem:
- Memória de Conversação: O modelo precisa se lembrar de interações passadas.
- Acesso a Dados Externos (RAG): O modelo precisa consultar documentos ou bases de dados que não estavam no seu treinamento original.
- Capacidade de Ação: O modelo precisa decidir quando usar uma ferramenta externa (ex: rodar código, buscar um CEP).
Na minha experiência ajudando clientes a escalar seus chatbots, logo no primeiro mês percebemos que a manutenção de estado (memória) de forma manual via código Python ou Node.js se tornava um pesadelo de latência e custo. É por isso que a comunidade migrou para orquestradores.
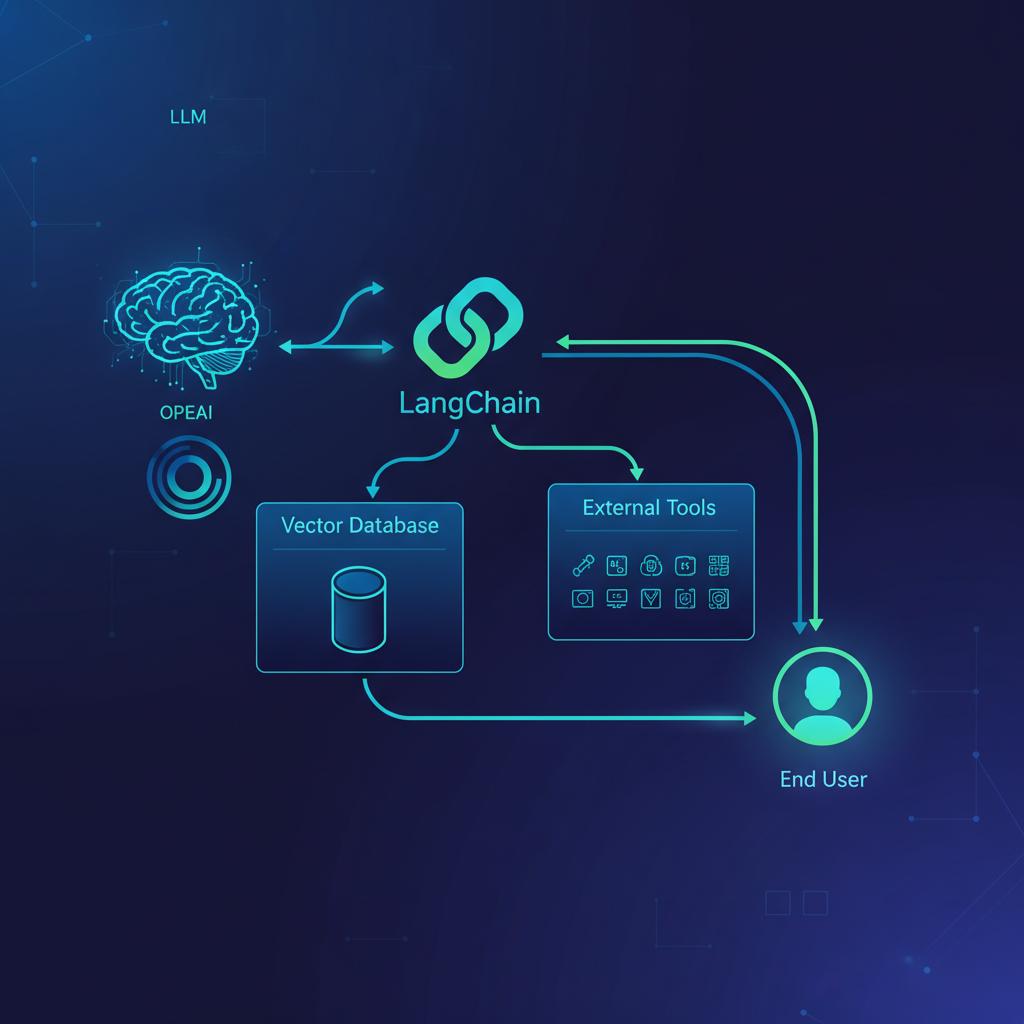
Por Que Escolher LangChain? A Arquitetura Modular
O LangChain não é um LLM; é um framework para desenvolver aplicações baseadas em LLMs. Ele oferece abstrações cruciais que transformam um modelo estatístico em um agente funcional.
Um dado importante do mercado: Pesquisas recentes indicam que mais de 70% dos desenvolvedores que criam aplicações complexas baseadas em modelos de linguagem utilizam algum tipo de framework de orquestração para gerenciar a complexidade do fluxo de dados (Fonte: Relatório de Tendências em AI 2024).
Os principais componentes do LangChain incluem:
- Models: Interfaces para se comunicar com LLMs (OpenAI, Anthropic, etc.).
- Prompts: Templates para gerenciar as entradas (instruções).
- Chains: Sequências pré-definidas de chamadas de componentes.
- Agents: O coração da lógica, onde o LLM decide qual ferramenta usar em seguida.
Construindo Aplicações Robustas com LangChain e OpenAI
A integração começa definindo qual provedor de LLM você usará. Para a maioria dos projetos de alta performance, a integração direta com a OpenAI é o caminho inicial, pois ela oferece os modelos mais avançados.
Configurando o Ambiente e Autenticação
Primeiramente, certifique-se de ter sua chave de API da OpenAI configurada como variável de ambiente. Isso é uma prática de segurança fundamental. Nunca exponha chaves diretamente no código-fonte.
# Exemplo de inicialização em Python com LangChain
import os
from langchain_openai import ChatOpenAI
# Assume que OPENAI_API_KEY está no seu ambiente
os.environ["OPENAI_API_KEY"] = "SUA_CHAVE_AQUI"
llm = ChatOpenAI(model="gpt-4o", temperature=0.5)
Dica de Insider: Muitas vezes, clientes tentam usar o modelo padrão para tudo. Meu conselho é experimentar com o parâmetro temperature. Para tarefas factuais (como um sistema de suporte técnico), mantenha-a baixa (0.1 a 0.3). Para geração criativa, suba para 0.7 ou mais. A otimização do temperature impacta drasticamente a previsibilidade da sua aplicação.
Implementando Memória (ConversationBufferMemory)
Um erro comum é esquecer que, por padrão, cada chamada à ChatGPT API é isolada. O LangChain resolve isso com o conceito de Memory.
Se você está rodando sua aplicação em uma infraestrutura como um VPS robusto (você pode conferir nossas ofertas em /comprar-vps-brasil para garantir a performance necessária para orquestração), você pode gerenciar a memória da sessão:
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
print(conversation.predict(input="Meu nome é Gabriel e eu trabalho com automação."))
print(conversation.predict(input="Qual o meu nome?"))
# O LLM deve responder 'Gabriel' com base na memória.
RAG: Conectando LLMs ao Seu Conhecimento Privado
A capacidade mais poderosa de uma inteligência artificial corporativa é consultar dados específicos da sua empresa. Isso é feito através da arquitetura RAG (Retrieval-Augmented Generation). Eu já ajudei clientes a implementar sistemas onde o LLM respondia a dúvidas complexas sobre manuais internos de mais de 1000 páginas.
O Processo de Indexação e Embeddings
O processo RAG envolve:
- Chunking: Dividir documentos grandes em pedaços gerenciáveis (chunks).
- Embeddings: Transformar esses chunks em vetores numéricos que capturam o significado semântico, usando modelos específicos (muitas vezes fornecidos pela própria OpenAI ou alternativas open source).
- Vector Store: Armazenar esses vetores em um banco de dados vetorial (como ChromaDB ou Pinecone).
Quando o usuário faz uma pergunta, a pergunta também é transformada em um vetor. O sistema busca os vetores mais próximos (semelhantes semanticamente) no Vector Store e injeta esses documentos originais no prompt do LLM. Isso é o que chamamos de Contextualização.
Evitando o Erro Comum: Context Window Overflow
Um erro frequente é tentar injetar documentos longos demais. Cada modelo LLM possui um limite de Context Window (o número máximo de tokens que ele pode processar de uma vez). Se você exceder esse limite, a API retornará um erro, ou, pior, o modelo pode ignorar informações cruciais no meio do prompt.
Solução Prática: Use `RecursiveCharacterTextSplitter` do LangChain para garantir que seus chunks sejam otimizados para o modelo que você está usando, priorizando a coerência semântica sobre o tamanho exato.
Agentes Inteligentes: A Próxima Fronteira da Automação
O verdadeiro poder da inteligência artificial surge quando o modelo pode tomar decisões sobre quais ações executar. Os Agentes no LangChain permitem isso. Eles utilizam o LLM como um motor de raciocínio que interage com um conjunto de Tools (Ferramentas).
Definindo Ferramentas para o Agente
Uma Tool é essencialmente uma função Python que o LLM pode decidir chamar. Por exemplo, você pode criar uma ferramenta para:
- Consultar o status de um pedido no seu banco de dados.
- Enviar um e-mail de notificação.
- Executar um script de N8N para iniciar um fluxo de trabalho de automação.
O processo se parece com isto:
- Usuário pergunta: "Qual o status do pedido #1234 e me envie um resumo por e-mail?"
- O Agente (usando o LLM) determina que precisa da
Tool_ConsultaPedidoe daTool_EnviarEmail. - Ele executa a primeira, recebe o resultado ("Status: Enviado").
- Ele usa o resultado para formatar o texto e decide chamar a segunda ferramenta.
- O agente retorna a resposta final ao usuário.
Essa orquestração autônoma economiza tempo de desenvolvimento e oferece uma experiência de usuário muito mais rica. Se você está interessado em automatizar processos complexos que envolvem múltiplas APIs, confira nossos guias sobre integração com N8N, pois é um excelente parceiro para as ferramentas que o LLM irá orquestrar.
Considerações de Custo e Performance com OpenAI
A performance e o custo são considerações vitais ao depender da OpenAI API, especialmente em aplicações de alto volume. Os modelos mais avançados (como o GPT-4o) são mais capazes, mas custam mais por token de entrada e saída.
Tabela de Custos Relativos (Estimativa, Valores Reais Flutuam):
| Modelo | Capacidade | Custo Relativo | Latência |
|---|---|---|---|
| GPT-3.5 Turbo | Bom/Rápido | Baixo (1x) | Baixa |
| GPT-4o | Excelente/Multimodal | Médio (3x) | Média-Baixa |
| GPT-4 Turbo | Alta Complexidade | Alto (5x) | Média |
Uma estatística interessante: A introdução do GPT-4o reduziu os custos de inferência em até 50% em comparação com o GPT-4 Turbo anterior, o que é um fator decisivo para quem hospeda muitas chamadas em sua infraestrutura de servidor.
Como a Host You Secure Ajuda: Hospedar sua aplicação de orquestração (onde o LangChain roda) exige recursos estáveis. Usar um VPS dedicado em nossa rede garante baixa latência entre sua aplicação e os endpoints da OpenAI, crucial para manter a fluidez das suas interações com o LLM.
Conclusão e Próximos Passos
A integração de LLMs como os da OpenAI utilizando o poder do LangChain move a inteligência artificial de um experimento de laboratório para uma ferramenta de negócios essencial. Você aprendeu a estruturar chamadas com memória, a implementar RAG para conhecimento específico e a criar agentes autônomos.
O próximo passo prático é refinar seu prompt engineering e testar diferentes modelos para otimizar a relação custo-benefício. Se você precisa de uma infraestrutura robusta e escalável para hospedar suas novas aplicações de IA, considere nossas soluções otimizadas. Comece a construir hoje mesmo com a base técnica correta!
Leia também: Veja mais tutoriais de N8N
Comentários (0)
Ainda não há comentários. Seja o primeiro!