Dominando LLMs: Guia Prático de Implementação e Automação com Inteligência Artificial
A revolução da inteligência artificial generativa, impulsionada por modelos como o GPT da OpenAI, não é mais ficção científica; é uma realidade operacional que está redefinindo a automação de processos e o desenvolvimento de software. Trabalhando diariamente com infraestrutura cloud e automação na Host You Secure, vejo o impacto direto que os LLMs (Large Language Models) têm na eficiência dos nossos clientes. Este artigo visa desmistificar a implementação prática desses modelos, focando em arquitetura, ferramentas e melhores práticas de infraestrutura.
A implementação eficaz de um LLM não se resume apenas a chamar a ChatGPT API; requer um entendimento de como orquestrar fluxos de trabalho complexos, gerenciar contextos de longa duração e garantir que a infraestrutura suporte a demanda. Para quem busca construir aplicações sérias baseadas em IA, é fundamental dominar o ecossistema ao redor desses modelos.
Arquitetura Essencial de Aplicações Baseadas em LLM
Quando falamos em aplicar LLMs em cenários de produção, raramente usamos apenas a chamada bruta ao modelo. A complexidade reside na necessidade de dar memória, acesso a dados externos e um fluxo de raciocínio estruturado ao modelo. Isso exige uma arquitetura bem definida.
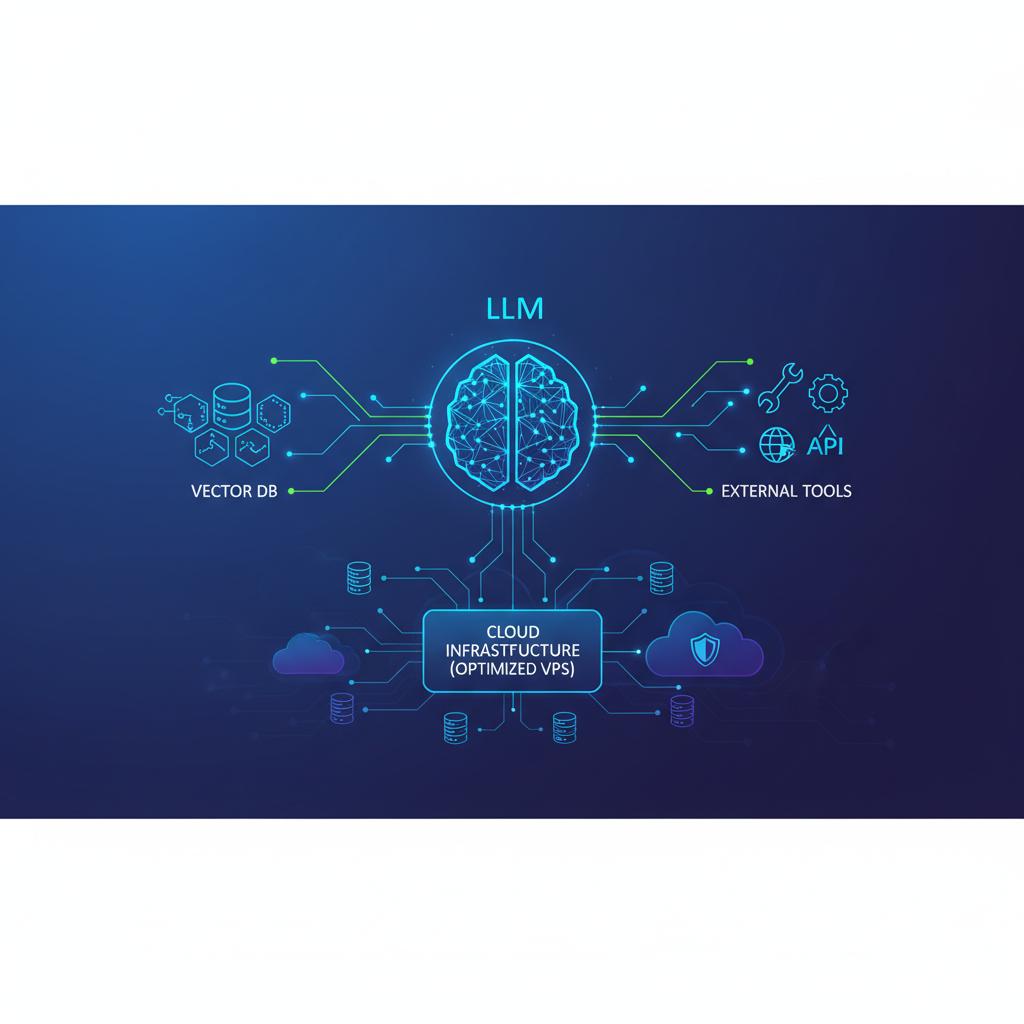
Componentes Chave de um Sistema LLM
Um sistema robusto baseado em LLM geralmente é composto por quatro elementos principais que trabalham em conjunto:
- O Modelo Base (Foundation Model): O LLM em si, seja um modelo proprietário acessado via API (ex: GPT-4) ou um modelo open-source hospedado localmente.
- O Mecanismo de Prompt Engineering: A arte e a ciência de formular as instruções (prompts) para obter a resposta desejada. Isso inclui o uso de few-shot learning e instruções de sistema.
- Camada de Contexto (Retrieval Augmented Generation - RAG): A capacidade de injetar conhecimento externo e específico do domínio no prompt. Geralmente, isso envolve bancos de dados vetoriais.
- Orquestração: O framework que conecta todos esses componentes em sequências lógicas ou 'cadeias' de processamento.
Por que a API da OpenAI não é Suficiente Sozinha?
A ChatGPT API é excelente para tarefas simples de geração de texto, sumarização ou tradução imediata. No entanto, ela tem limitações inerentes: custo por token, latência variável para aplicações críticas e a falta de acesso a dados internos e proprietários da sua empresa. Na minha experiência, já ajudei clientes que tentaram usar a API diretamente para criar chatbots de suporte técnico e falharam porque o modelo não tinha acesso ao manual de produtos mais recente. A solução foi implementar RAG, onde os documentos são indexados e recuperados antes de serem enviados ao LLM. Estima-se que 60% dos projetos de IA corporativa que visam a adoção em produção utilizam alguma forma de RAG para manter a relevância factual.
O Poder da Orquestração com Frameworks: Introdução ao LangChain
Para transformar um modelo de linguagem isolado em uma aplicação funcional, precisamos de um orquestrador. É aqui que frameworks como LangChain brilham. LangChain não é um LLM; é uma biblioteca que facilita a criação de cadeias complexas de raciocínio (chains) e agentes que podem interagir com o mundo exterior (outras APIs, bancos de dados, etc.).
Criando Cadeias de Pensamento (Chains)
O conceito central do LangChain são as Chains. Uma Chain é uma sequência de componentes, onde a saída de um se torna a entrada do próximo. Por exemplo, uma Chain pode:
- Receber a entrada do usuário.
- Chamar um LLM para formatar a pergunta em uma consulta SQL.
- Executar a consulta SQL no banco de dados (usando uma ferramenta).
- Passar o resultado da consulta de volta ao LLM para gerar uma resposta amigável ao usuário.
Esta abordagem é significativamente mais poderosa do que um único prompt. É o que permite a automação de tarefas que exigem múltiplos passos de raciocínio.
Agentes: LLMs que Tomam Decisões
Agentes são o próximo nível de sofisticação. Um Agente usa um LLM como seu 'cérebro' para decidir qual ferramenta usar em seguida para atingir um objetivo. Se você tem um agente com acesso a uma ferramenta de busca na web, uma ferramenta de cálculo e uma ferramenta de envio de e-mail, ele pode raciocinar: 'Para responder a esta pergunta, preciso primeiro buscar dados recentes, depois realizar um cálculo e, finalmente, notificar o usuário.'
Dica de Insider: Ao usar LangChain, não superestime a capacidade do LLM de escolher a ferramenta certa no início. Sempre forneça instruções muito claras sobre quando e por que usar cada ferramenta. O erro comum é permitir que o modelo divague entre ferramentas sem um controle rígido, resultando em ciclos infinitos ou custos elevados.
Infraestrutura: Onde Hospedar Seus Modelos e Aplicações
A escolha da infraestrutura é vital, especialmente quando você começa a migrar de APIs pagas para modelos self-hosted ou quando a latência das chamadas à API externa se torna um gargalo.
VPS Dedicada vs. Serviços Gerenciados
Para a maioria das integrações baseadas em API (OpenAI, Anthropic), um VPS robusto com boa conectividade de rede é suficiente para rodar o código de orquestração (LangChain, Python, etc.). A vantagem de um VPS é o controle total sobre o ambiente, segurança e, crucialmente, o custo fixo mensal, o que é mais previsível do que o pay-per-use de algumas plataformas serverless.
No entanto, se você optar por hospedar modelos open-source de ponta (como versões do Llama ou Mistral), você precisará de infraestrutura especializada. Modelos maiores exigem GPUs potentes e grande quantidade de VRAM. Para esses casos, nós recomendamos nossos planos de Servidores Dedicados ou instâncias cloud otimizadas para IA, pois um VPS padrão não terá o poder de processamento necessário para inferência em tempo real.
Segundo dados recentes do mercado, a infraestrutura de IA cresce 30% ao ano, e a principal restrição para a adoção de modelos abertos é o custo/acesso à GPU. Se você está começando com automação e precisa apenas orquestrar chamadas API, um bom VPS no Brasil, como os oferecidos pela Host You Secure, garante baixa latência para o tráfego local e desempenho consistente. Confira nossos planos de VPS otimizados para desenvolvimento aqui.
Gerenciamento de Credenciais e Segurança
Ao trabalhar com a ChatGPT API, suas chaves de acesso (API keys) são o ouro digital. Em minhas auditorias de segurança, este é um ponto de falha comum. Jamais armazene chaves diretamente no código-fonte ou em repositórios públicos.
Utilize sempre:
- Variáveis de Ambiente (Environment Variables) para passar as chaves para o servidor.
- Vaults de segredos (como HashiCorp Vault ou AWS Secrets Manager) em ambientes de produção complexos.
- Limitação de uso e monitoramento rigoroso das chaves na plataforma da OpenAI.
Desafios Comuns na Implementação de LLMs
A jornada de adoção de LLMs é cheia de armadilhas. Baseado em projetos que supervisionei, os principais problemas não são a tecnologia em si, mas a aplicação dela no mundo real.
Alucinações e Veracidade dos Dados
O maior desafio técnico continua sendo a tendência do LLM de 'alucinar' – inventar fatos convincentes, mas falsos. A implementação de RAG (Retrieval Augmented Generation) ajuda enormemente, mas não elimina o risco. Sempre valide a saída de um modelo em fluxos críticos. Para aplicações financeiras ou médicas, a intervenção humana no loop (Human-in-the-Loop) é mandatória.
Gerenciamento de Custos e Latência
Um erro comum que vi acontecer é um desenvolvedor usar o modelo mais caro (ex: GPT-4 Turbo) para tarefas triviais, como validação de formato de e-mail. Isso destrói o orçamento rapidamente.
Regra de Ouro: Use o modelo mais barato e rápido que atenda aos requisitos de qualidade para cada etapa da sua Chain. Você pode usar um modelo leve e rápido para pré-processamento e roteamento, e só acionar o modelo pesado (e caro) para a geração final complexa. Gerenciar essa lógica de roteamento é outra função primária do LangChain.
O Futuro: LLMs e Automação Integrada
A tendência aponta para sistemas de inteligência artificial cada vez mais autônomos, capazes de planejar e executar tarefas multi-etapas usando ferramentas variadas. Veremos uma convergência entre LLMs e RPA (Robotic Process Automation) tradicional.
A Host You Secure está focada em fornecer a base estável e performática (VPS, infraestrutura de contêineres) para que as empresas possam focar na lógica da IA, sem se preocupar com o uptime do servidor ou a conectividade. Entender como atuar no desenvolvimento de software é essencial, mas a infraestrutura é o alicerce.
Conclusão e Próximos Passos
Dominar os LLMs exige mais do que apenas conhecer a OpenAI. Requer proficiência em orquestração (LangChain), uma estratégia de dados sólida (RAG) e infraestrutura confiável. A adoção bem-sucedida transforma processos de negócios, mas exige planejamento técnico rigoroso.
Se você está pronto para levar sua automação com IA para o próximo nível, mas precisa de uma fundação de infraestrutura sólida e escalável, entre em contato com a equipe da Host You Secure. Estamos prontos para fornecer a VPS ideal para suportar suas inovações em inteligência artificial. Para aprender mais sobre automação avançada e infraestrutura, explore nosso blog.
Leia também: Veja mais tutoriais de N8N
Comentários (0)
Ainda não há comentários. Seja o primeiro!