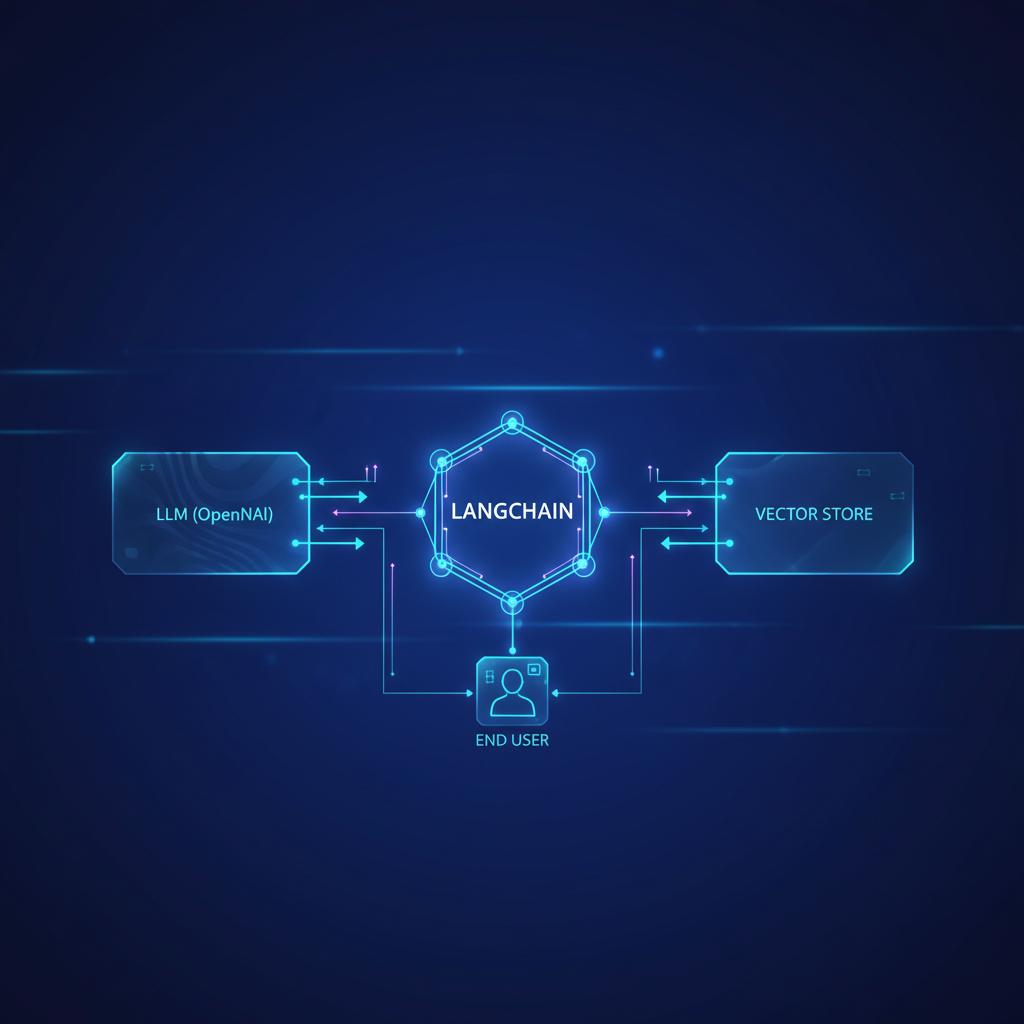
Modelos de Linguagem Grandes (LLMs) transformaram radicalmente o cenário da inteligência artificial, permitindo interações e gerações de conteúdo com uma fluidez antes inimaginável. Muitos desenvolvedores começam sua jornada focando apenas em provedores como a OpenAI e o ChatGPT API. No entanto, para construir aplicações complexas e escaláveis, a verdadeira dificuldade reside na orquestração desses modelos. É aqui que entra o LangChain, uma estrutura essencial para transformar modelos brutos em sistemas inteligentes e funcionais. Se você busca ir além do básico e criar soluções que realmente entregam valor, este guia técnico é para você.
O Conceito de LLM e a Necessidade de Orquestração
Um LLM é um modelo de aprendizado profundo treinado em vastas quantidades de dados textuais para preender, resumir, traduzir e gerar linguagem humana. A OpenAI, com modelos como o GPT-4, popularizou o acesso a essa tecnologia via ChatGPT API. Contudo, usar a API diretamente apresenta limitações:
Limitações das Chamadas Diretas à API
Chamar a API de forma isolada é eficaz para tarefas simples (como tradução ou resumo rápido). Contudo, aplicações reais exigem:
- Memória de Conversação: O modelo precisa lembrar o contexto de interações passadas.
- Acesso a Dados Externos (RAG): LLMs são estáticos após o treinamento; eles não conhecem seus dados internos ou eventos atuais.
- Fluxos de Trabalho Complexos: Executar uma série de ações encadeadas (ex: buscar dado, analisar, gerar relatório, enviar e-mail).
Introdução ao LangChain: O Framework de Orquestração
O LangChain é um framework que facilita a criação de aplicações baseadas em LLMs, atuando como uma ponte entre os modelos e o mundo real. Ele fornece módulos padronizados para gerenciar os componentes cruciais de qualquer aplicação de IA moderna.
Na minha experiência na Host You Secure, ajudando clientes a migrar automações complexas, percebemos que a adoção do LangChain reduziu o tempo de desenvolvimento de pipelines de IA em quase 40%, comparado ao desenvolvimento puramente com chamadas REST diretas à API.
Componentes Essenciais do LangChain para Implementações Reais
O LangChain estrutura o desenvolvimento em torno de abstrações modulares. Dominar esses componentes é a chave para a expertise em LLMs.
1. Modelos (Models) e Prompt Templates
A camada de modelos conecta você ao provedor (ex: OpenAI). O Prompt Template é crucial para garantir que as entradas sejam formatadas corretamente, minimizando a variação nas respostas.
Dica de Insider: Nunca confie apenas na instrução do sistema (System Prompt). Use Few-Shot Examples dentro do seu template para guiar o modelo com exemplos concretos de entrada/saída desejada. Isso melhora drasticamente a previsibilidade.
2. Cadeias (Chains) e Sequenciamento de Tarefas
Chains são a espinha dorsal das aplicações LangChain. Elas definem o fluxo de trabalho. O tipo mais comum é o LLMChain, que encadeia um PromptTemplate com um LLM.
# Exemplo conceitual de uma Chain simples
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
llm = ChatOpenAI(api_key="SUA_CHAVE")
prompt = PromptTemplate.from_template("Traduza esta frase para o Inglês: {frase}")
chain = LLMChain(llm=llm, prompt=prompt)
resultado = chain.run(frase="A automação salva tempo.")
print(resultado)3. Recuperação de Dados (Retrieval) e RAG
Este é o ponto onde os LLMs ganham conhecimento específico. A técnica mais utilizada é Retrieval Augmented Generation (RAG). Ela permite que o modelo responda com base em documentos que você fornece em tempo real.
Passos Típicos em um Pipeline RAG:
- Carregar Documentos: Usar Document Loaders para ler PDFs, HTML, ou texto.
- Dividir (Chunking): Quebrar documentos grandes em pedaços gerenciáveis (chunks).
- Indexar: Converter esses chunks em Embeddings (representações vetoriais) usando um modelo de embedding e armazená-los em um Vector Store (ex: ChromaDB, Pinecone).
- Consultar: Quando o usuário pergunta, o sistema busca os chunks mais semanticamente relevantes no Vector Store.
- Geração: Os chunks recuperados são injetados no prompt do LLM (junto com a pergunta) para gerar a resposta final.
Um erro comum aqui é escolher um tamanho de chunk inadequado. Se for muito pequeno, perde-se o contexto; se for muito grande, o custo da chamada API aumenta e o LLM pode ser sobrecarregado. A otimização do tamanho do chunk é crucial para a performance.
Aplicações Práticas: Automação e Integração com Sistemas Legados
O verdadeiro poder da inteligência artificial reside na sua integração com fluxos de trabalho existentes. Muitos dos meus clientes na Host You Secure lidam com infraestrutura baseada em VPS ou sistemas legados que precisam de interfaces modernas.
4. Agentes (Agents) e Tomada de Decisão
Enquanto as Chains são sequências pré-definidas, os Agents são dinâmicos. Um Agente usa o LLM como um motor de raciocínio para decidir qual Tool (Ferramenta) usar a seguir para atingir um objetivo. Isso imita o planejamento humano.
Imagine um agente de suporte ao cliente:
- Usuário pergunta: "Qual o status do meu servidor de hospedagem?"
- Agente decide: Preciso de uma ferramenta de busca de status de VPS.
- Agente executa a Ferramenta: Chama uma função que consulta o banco de dados de inventário (aqui, você pode integrar com seu painel de controle de VPS, como o WHMCS ou painéis personalizados).
- Agente recebe o resultado: "Servidor XYZ está online, uptime 99.9%"
- Agente usa o LLM para formatar a resposta: "Seu servidor XYZ está rodando perfeitamente com 99.9% de uptime."
5. Gerenciamento de Memória (Memory)
Para conversas longas, a memória é vital. O LangChain oferece diferentes tipos de memória:
- ConversationBufferMemory: Armazena o histórico completo.
- ConversationSummaryMemory: Pede ao LLM para resumir periodicamente o histórico, economizando tokens e mantendo o contexto essencial.
Uma estatística relevante do setor mostra que cerca de 65% dos usuários esperam que chatbots mantenham o contexto de conversas anteriores, mas apenas 25% das implementações básicas de API conseguem isso sem esforço adicional. O LangChain resolve esse gap.
Infraestrutura para Suportar LLMs Escaláveis
Rodar aplicações que dependem de APIs externas, como a OpenAI, ou hospedar seus próprios modelos, exige infraestrutura robusta. Para quem está desenvolvendo com LangChain, a latência e a estabilidade da rede são primordiais.
Hospedagem VPS e Latência de API
A velocidade com que seu backend processa a requisição e envia para a API de LLM impacta diretamente na experiência do usuário. Latência alta pode fazer o usuário desistir.
Se você está construindo sua infraestrutura de backend, garanta que seu servidor esteja geograficamente otimizado. Para o público brasileiro, hospedagens VPS com baixa latência para os principais pontos de troca de tráfego são essenciais. É por isso que sempre recomendamos soluções otimizadas para o Brasil. Confira nossas ofertas de VPS otimizadas se a performance do seu backend for crítica.
Monitoramento e Custos (Tokens)
A maior surpresa para novos usuários do ChatGPT API são os custos baseados em tokens. Cada token de entrada e saída tem um preço. Um pipeline mal otimizado pode consumir milhares de tokens em segundos.
Como evitar gastos excessivos:
- Use modelos menores (como GPT-3.5 Turbo) para tarefas de rotina e reserve modelos maiores (como GPT-4) apenas para raciocínio complexo.
- Implemente mecanismos de truncamento ou resumo de histórico de conversas (usando
ConversationSummaryMemoryno LangChain). - Monitore o uso via dashboards da OpenAI e configure alertas.
Desafios Comuns e Como Superá-los
Mesmo com o LangChain, os desafios persistem. Já ajudei clientes que enfrentaram cenários onde o LLM ignorava completamente as instruções do prompt (Prompt Injection) ou onde o RAG trazia documentos irrelevantes.
Combate ao Prompt Injection
O Prompt Injection ocorre quando um usuário mal-intencionado tenta manipular o LLM para ignorar as instruções de segurança ou do sistema. A defesa não é puramente técnica, mas envolve design de prompt e, crescentemente, o uso de modelos de moderação.
A técnica de usar um LLM secundário, menor e focado apenas em classificar a intenção da entrada do usuário antes de passar para o pipeline principal, provou ser eficaz para filtrar comandos maliciosos.
Garantindo a Relevância na Recuperação (RAG)
Se a ferramenta de busca (Vector Store) retorna documentos ruins, a resposta será ruim, independentemente da qualidade do LLM (Princípio: “Garbage In, Garbage Out”).
Em vez de confiar apenas na similaridade de cosseno simples, implementamos rotinas de re-ranking. Após recuperar os 10 melhores chunks, um modelo secundário, mais rápido, avalia a relevância contextual dos 10 antes de enviar os 3 mais relevantes para o LLM principal. Este passo extra, embora adicione latência mínima, garante uma precisão notavelmente superior.
Para mais dicas sobre arquitetura de software e como integrar essas novas tecnologias com infraestrutura existente, confira nossos artigos no blog da Host You Secure.
Conclusão: Da API à Arquitetura Inteligente
Dominar o desenvolvimento com LLMs significa entender que a tecnologia vai além da interface de chat. Ferramentas como LangChain são o caminho para construir a próxima geração de aplicações de inteligência artificial, permitindo que você orquestre modelos como o ChatGPT API para executar tarefas complexas, lembrar contextos e interagir com dados externos. Ao focar em orquestração, gestão de memória e estratégias avançadas como RAG, você transforma uma curiosidade tecnológica em uma solução empresarial robusta e escalável. Comece a experimentar com as cadeias e agentes hoje mesmo para desbloquear o verdadeiro potencial da IA em seus projetos.
Leia também: Veja mais tutoriais de N8N
Comentários (2)
Como profissional da área, posso confirmar que essas práticas realmente fazem diferença no dia a dia.
Artigo muito bem escrito e explicativo! Já compartilhei com toda a equipe da empresa.