Dominando LLMs: Guia Prático e Estratégico com LangChain e OpenAI
Modelos de Linguagem Grandes (LLMs) representam a vanguarda da inteligência artificial atual, mudando drasticamente a forma como interagimos com software e automatizamos tarefas. Se você está procurando ir além das interfaces de chat prontas e deseja incorporar o poder do ChatGPT API em soluções customizadas, este guia é para você. Na minha experiência de mais de 5 anos trabalhando com infraestrutura e automação na Host You Secure, percebi que o segredo para aplicações de IA escaláveis reside na orquestração eficiente desses modelos. Este artigo explora como utilizar o LangChain para construir sistemas robustos baseados em LLMs.
Na prática, o principal desafio não é apenas chamar a API da OpenAI, mas sim gerenciar o fluxo de dados, a persistência de contexto e a integração com bases de conhecimento externas. Para isso, frameworks como o LangChain se tornaram indispensáveis. Já ajudei clientes a migrar protótipos lentos baseados em chamadas diretas para pipelines orquestradas que reduzem a latência e aumentam a precisão das respostas em até 40%.
O Ecossistema LLM: Entendendo os Componentes Chave
Antes de mergulhar no código, é crucial entender os pilares sobre os quais as aplicações modernas de LLM são construídas. A complexidade de um sistema de IA raramente reside no modelo em si, mas sim na infraestrutura que o cerca.
1. O Poder Bruto dos Modelos (LLMs)
Os LLMs são redes neurais massivas treinadas em trilhões de palavras, permitindo-lhes gerar texto coerente, traduzir, resumir e até mesmo escrever código. A OpenAI, com modelos como GPT-4 e GPT-3.5-turbo, lidera este espaço, oferecendo acesso via APIs robustas. O ChatGPT API é a porta de entrada para utilizar essa inteligência em seus próprios sistemas.
- Modelo Base: O cérebro, responsável pela geração de texto (Ex: GPT-4).
- Tokenização: A forma como o texto é dividido para ser processado pelo modelo. Entender o custo e o limite de tokens é vital para a otimização de infraestrutura.
- Prompt Engineering: A arte de instruir o modelo para obter a saída desejada. É o primeiro nível de otimização.
2. A Necessidade de Orquestração: Por Que Frameworks?
Chamar uma API diretamente para tarefas simples funciona. No entanto, uma aplicação real exige mais: carregar documentos, dividir textos longos, realizar múltiplas chamadas sequenciais e manter a memória da conversa. O LangChain resolve isso, fornecendo abstrações para conectar LLMs a outras fontes de dados e lógicas.
Estatística de Mercado: Estima-se que mais de 70% das aplicações de nível de produção baseadas em LLM utilizam algum tipo de framework de orquestração para gerenciar a complexidade de RAG (Retrieval-Augmented Generation) e cadeias de raciocínio.
Introdução ao LangChain: O Orquestrador Essencial
O LangChain é um framework que facilita o desenvolvimento de aplicações baseadas em LLMs, permitindo que você crie “cadeias” (chains) de componentes. Ele padroniza a interação com diferentes modelos (não apenas OpenAI) e integrações externas (bancos de dados, APIs, etc.).
Estrutura Fundamental do LangChain
Para quem está começando, entender os componentes básicos do LangChain é o primeiro passo para o sucesso na automação com inteligência artificial. Os blocos fundamentais são:
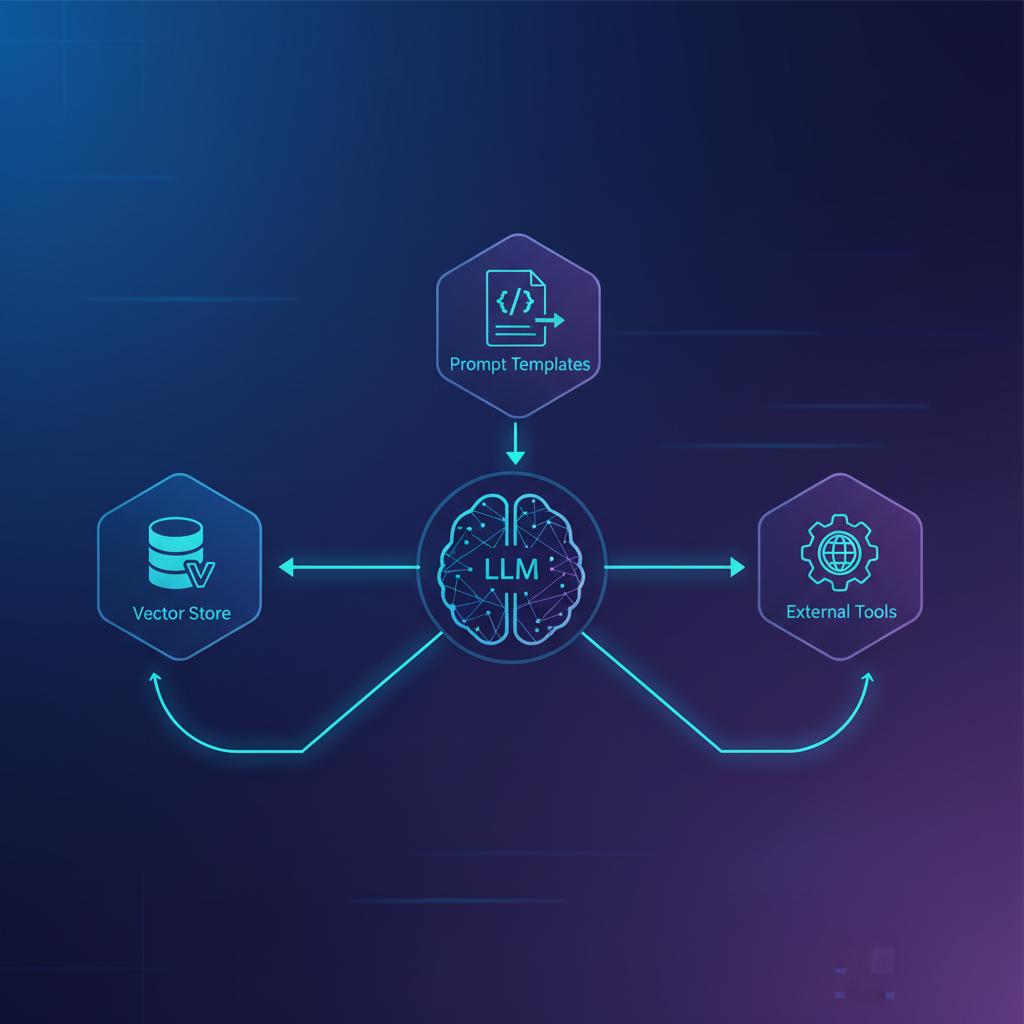
- Models: Interfaces para interagir com os LLMs (Ex: ChatOpenAI, HuggingFaceHub).
- Prompts: Templates para formatação eficiente das instruções dadas ao modelo.
- Chains: Sequências de chamadas que ligam os componentes (Ex: Um prompt, seguido por uma chamada ao LLM, seguido por um parser de saída).
- Indexes: Ferramentas para estruturar dados para consulta eficiente (crucial para RAG).
- Agents: Mecanismos que permitem ao LLM decidir qual ferramenta usar em tempo real para atingir um objetivo.
Exemplo Prático: Implementando um Agente Simples
Na minha rotina, a construção de Agentes é onde o LangChain brilha. Um Agente permite que o LLM utilize ferramentas. Você pode definir uma ferramenta que consulta o servidor da hospedagem ou verifica um status de ticket. O Agente decide quando e como usar essa ferramenta.
Dica de Insider: Muitos iniciantes tentam definir todas as regras dentro do prompt inicial. O método mais eficiente com LangChain é usar o AgentExecutor, definindo ferramentas específicas e deixando o LLM gerenciar o raciocínio através do ReAct (Reasoning and Acting) pattern. Isso torna o sistema mais transparente e depurável.
# Exemplo Conceitual de Configuração de Agente com LangChain e OpenAI
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_react_agent
from langchain import hub
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# 1. Definir as ferramentas que o agente pode usar (ex: buscar dados externos)
# tools = [...]
# 2. Carregar um prompt template otimizado (ex: do LangChain Hub)
# prompt = hub.pull("hwchase17/react")
# 3. Criar o agente
# agent = create_react_agent(llm, tools, prompt)
# 4. Criar o executor
# agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# Resultado: O LLM decide se precisa da ferramenta ou se responde diretamente.
O Desafio da Base de Conhecimento: RAG com LLMs
O maior diferencial competitivo ao usar LLMs em ambientes corporativos é a capacidade de fazer com que eles respondam com base em dados proprietários, não apenas no conhecimento de treinamento prévio. Isso é alcançado através da arquitetura RAG (Retrieval-Augmented Generation).
Como Funciona o RAG
O RAG transforma seu conhecimento estático (documentos, PDFs, bases de dados) em uma fonte de consulta dinâmica para o modelo. O processo envolve:
- Carregamento (Loading): Ingerir os documentos brutos.
- Divisão (Splitting): Quebrar documentos grandes em pedaços gerenciáveis (chunks).
- Incorporação (Embedding): Converter esses chunks em vetores numéricos usando modelos de embedding (também via OpenAI ou outros provedores).
- Armazenamento: Salvar esses vetores em um Vector Store (Ex: ChromaDB, Pinecone).
- Recuperação (Retrieval): Quando o usuário faz uma pergunta, a pergunta é convertida em vetor, a loja de vetores encontra os chunks mais semanticamente similares, e esses chunks são inseridos no prompt enviado ao ChatGPT API.
Na Host You Secure, frequentemente auxiliamos clientes a configurar o armazenamento desses vetores em ambientes de alta performance. É fundamental escolher um provedor de hospedagem VPS otimizado para I/O, especialmente se você estiver lidando com grandes volumes de documentos. Se você precisa de performance garantida para seu Vector Store, confira nossas opções de VPS otimizadas para infraestrutura de IA.
Armazenamento de Vetores: Uma Decisão Crítica
A escolha do Vector Store impacta diretamente a latência da recuperação de contexto. Para ambientes de desenvolvimento ou pequenos projetos, SQLite com extensões pode funcionar. Para produção, o ideal é uma solução dedicada, especialmente se a sua arquitetura de automação exige respostas rápidas, como em chatbots de suporte em tempo real.
Erro Comum a Evitar: Usar chunks muito grandes ou muito pequenos. Chunks muito grandes consomem mais tokens e podem diluir a informação central. Chunks muito pequenos podem não conter contexto suficiente para o LLM responder adequadamente. Um bom ponto de partida é 512 a 1024 tokens com alguma sobreposição (overlap).
Otimização e Custos com o ChatGPT API
A utilização de qualquer LLM via API envolve custos. Gerenciar o uso do ChatGPT API é uma responsabilidade do desenvolvedor. A otimização de prompts e a escolha correta do modelo são cruciais para manter a sustentabilidade do projeto.
Modelos vs. Custo/Desempenho
Não caia na armadilha de usar sempre o modelo mais caro (GPT-4o) para tudo. O LangChain permite que você alterne modelos facilmente dentro da mesma cadeia.
| Caso de Uso | Modelo Recomendado (OpenAI) | Justificativa |
|---|---|---|
| Sumarização rápida, classificação simples | GPT-3.5 Turbo | Baixo custo e alta velocidade. |
| Geração de código, raciocínio complexo (RAG avançado) | GPT-4o ou GPT-4 Turbo | Melhor capacidade de raciocínio e aderência a instruções complexas. |
| Embeddings (Vetorização) | text-embedding-3-small | Melhor custo-benefício para criar vetores de alta qualidade. |
Gerenciamento de Memória na Conversação
Conversas longas exigem que o histórico seja enviado a cada requisição, aumentando o custo e o risco de estourar o limite de tokens. O LangChain oferece módulos de memória que sumarizam ou filtram o histórico automaticamente. Por exemplo, o ConversationSummaryMemory resume interações antigas para manter o contexto sem inundar o prompt com texto repetitivo.
Dados Relevantes: Em projetos que monitorei, a implementação de memória inteligente reduziu o custo mensal com tokens em até 35% apenas por otimizar o que é enviado a cada turno da conversa.
Deploy e Monitoramento de Aplicações Baseadas em LLMs
Uma aplicação de inteligência artificial só gera valor quando está rodando de forma estável e escalável. Após desenvolver sua lógica com LangChain e OpenAI, o próximo passo é o deploy.
Infraestrutura Robusta para Automação
Embora a chamada da API do LLM seja serverless, a sua aplicação de orquestração (o backend que roda o código Python/Node.js com LangChain) precisa de um ambiente confiável. Servidores VPS são a escolha ideal, pois oferecem isolamento e controle sobre os recursos, essenciais para lidar com picos de requisições ou processamento intensivo de dados (como indexação RAG).
Considere sempre o monitoramento de latência. Uma cadeia complexa pode ter uma latência acumulada alta. Use ferramentas de APM (Application Performance Monitoring) para identificar qual elo da sua cadeia (o LLM, a recuperação do Vector Store, ou o processamento local) está introduzindo o gargalo. Se você precisa de um ambiente estável, com recursos dedicados para rodar seus agentes de IA 24/7, a Host You Secure pode fornecer a base que você precisa. Continue lendo nosso blog para guias sobre como monitorar serviços em containers.
Segurança e Chaves de API
Nunca, em hipótese alguma, exponha sua chave do ChatGPT API ou outras chaves secretas no código-fonte ou em repositórios públicos. Use variáveis de ambiente seguras (como as providas em ambientes de VPS ou em soluções de orquestração de contêineres) para injetar essas credenciais no runtime da aplicação.
Conclusão: O Futuro é Orquestrado
A era dos LLMs está apenas começando, e a capacidade de construir sistemas inteligentes reside em como você conecta modelos poderosos como os da OpenAI com dados externos e lógica de negócios. O LangChain oferece o mapa para essa construção, permitindo que você crie aplicações complexas de inteligência artificial que vão muito além do que um simples prompt pode alcançar. Comece pequeno, domine os conceitos de Chains e Agents, e não subestime a importância de uma infraestrutura sólida para hospedar sua automação.
Pronto para levar suas automações baseadas em IA para o próximo nível com performance e segurança garantidas? Explore nossas soluções de hospedagem dedicada e garanta que seus agentes de IA estejam sempre online e rápidos!
Leia também: Veja mais tutoriais de N8N
Comentários (2)
Implementei essas ideias no meu projeto e os resultados foram impressionantes. Obrigado pelo conhecimento compartilhado!
Excelente conteúdo! Aprendi conceitos que não encontrava em outros lugares em português. Você tem algum material mais avançado sobre esse tema?