Vector Databases: O Guia Definitivo para Busca Semântica e IA Generativa
A explosão da Inteligência Artificial Generativa e dos Large Language Models (LLMs) trouxe à tona uma necessidade crítica de novas formas de gerenciar e recuperar informações contextuais. É aqui que entram as Vector Databases. Se você está construindo qualquer aplicação que exija que a máquina 'entenda' o significado por trás do texto, imagem ou áudio, você precisará de uma. Na Host You Secure, temos implementado estas soluções para clientes que vão desde chatbots avançados até sistemas de recomendação complexos. Este artigo detalha o que são, por que são vitais e como começar a usá-las.
A resposta direta é: Vector Databases são essenciais para aplicações de IA que necessitam de compreensão contextual, funcionando como a memória de longo prazo para LLMs através do mecanismo RAG (Retrieval-Augmented Generation).
O Paradigma da Busca Semântica: Por Que Vetores São o Futuro
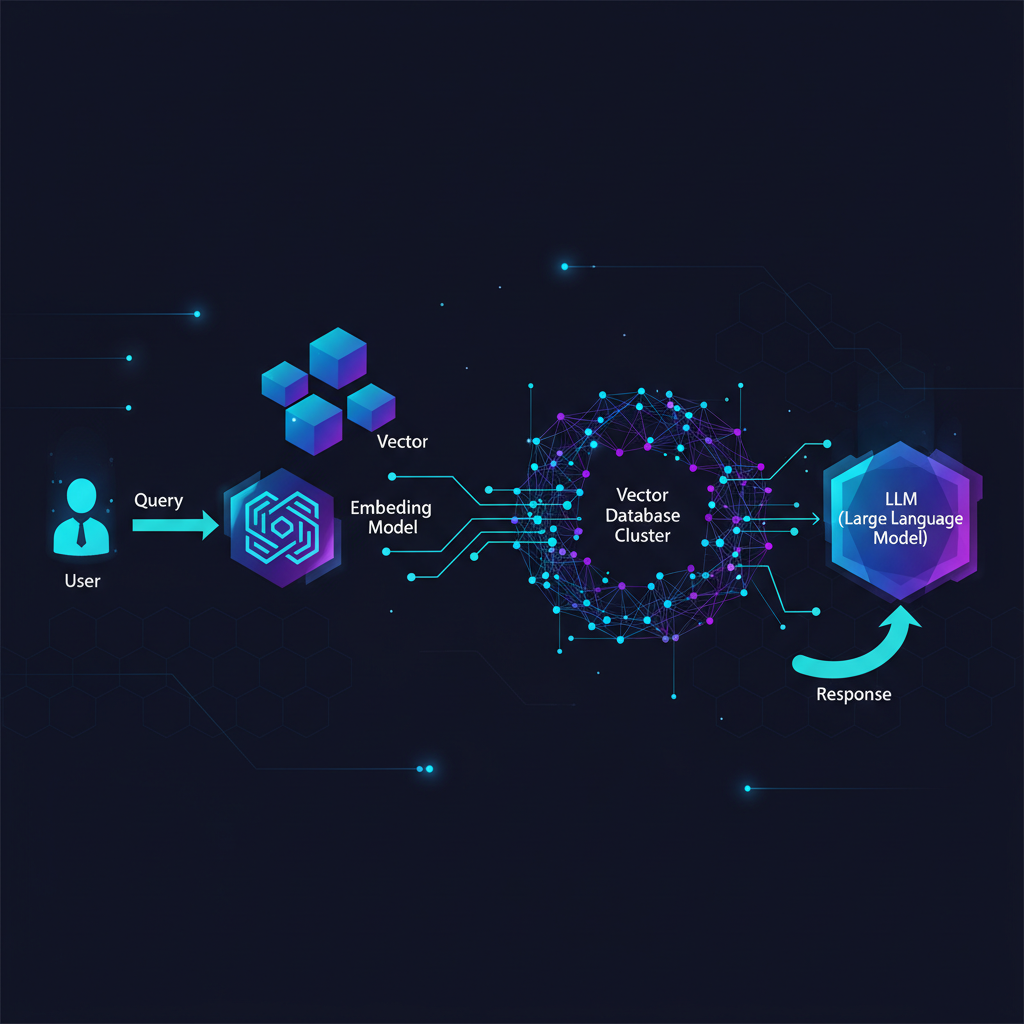
Sistemas de busca tradicionais, como os baseados em SQL ou ElasticSearch, operam com base em correspondência exata de palavras-chave ou proximidade lexical. Se você busca "computador rápido", mas o documento diz "máquina veloz", a busca tradicional pode falhar. A IA resolve isso transformando dados em embeddings.
O que são Embeddings e Como Eles Funcionam?
Embeddings são representações numéricas (vetores de alta dimensão) criadas por modelos de Machine Learning (como BERT ou modelos de linguagem). Esses vetores capturam o significado semântico do dado original. Vetores que estão semanticamente próximos no espaço vetorial (medido pela distância do cosseno ou distância Euclidiana) representam conceitos ou objetos similares.
Dado um exemplo prático: Já ajudei clientes a migrar sistemas legados de FAQs. Ao converter todas as perguntas e respostas em embeddings, conseguimos que uma busca por "Como resgato meu dinheiro?" encontrasse a resposta "Procedimento para saque de fundos", algo impossível com busca por texto simples. Isso representa um salto de precisão notável.
A Necessidade de um Banco de Dados Vetorial
Armazenar milhões desses vetores e, crucialmente, ser capaz de consultá-los rapidamente, exige otimização especializada. Bancos de dados relacionais ou NoSQL tradicionais não são projetados para a indexação eficiente em espaços multidimensionais. Os Vector Databases utilizam algoritmos especializados, como HNSW (Hierarchical Navigable Small World), para realizar a Busca de Vizinho Mais Próximo Aproximado (ANN) em milissegundos, mesmo com bilhões de vetores.
Estatística de Mercado: Segundo a Gartner, espera-se que o uso de vetores e bases de dados vetoriais cresça exponencialmente nos próximos anos, impulsionando a adoção de IA conversacional em ambientes corporativos. Estima-se que, até 2026, mais de 60% das organizações que utilizam IA em produção farão uso intensivo de indexação vetorial.
RAG: A Arquitetura que Transforma LLMs
O maior desafio dos LLMs (como GPT-4) é que seu conhecimento é estático (baseado na data de seu treinamento) e eles são propensos a alucinações (gerar informações falsas, mas convincentes). A arquitetura RAG (Retrieval-Augmented Generation) resolve isso.
Entendendo a Arquitetura RAG
O RAG é um pipeline onde a consulta do usuário não vai diretamente para o LLM. Ele segue os seguintes passos:
- Vetorização da Consulta: A pergunta do usuário é convertida em um vetor usando um modelo de embedding.
- Recuperação (Retrieval): O vetor da consulta é enviado ao Vector Database para encontrar os $K$ vetores mais similares (os documentos de contexto mais relevantes).
- Aumento (Augmentation): Os trechos de texto recuperados são anexados à solicitação original (o 'prompt').
- Geração (Generation): O prompt aumentado é enviado ao LLM, que agora tem o contexto factual necessário para gerar uma resposta precisa e fundamentada.
Dica de Insider: A qualidade da sua base vetorial determina 80% da performance do RAG. Investir em um bom modelo de embedding (não apenas o padrão) e em uma estratégia robusta de chunking (divisão dos documentos) é mais crucial do que o poder de processamento do LLM em si. Para hospedagem robusta e otimizada desses pipelines, você pode considerar nossas soluções de hospedagem VPS otimizada.
A Importância da Latência na Recuperação
Como o RAG adiciona uma etapa extra (a consulta ao banco de dados), a latência se torna um fator crítico na experiência do usuário. Se a busca vetorial demorar 5 segundos, a aplicação parecerá lenta. Isso reforça a necessidade de índices ANN altamente eficientes oferecidos pelas Vector Databases.
Principais Vector Databases do Mercado Atual
A escolha da ferramenta depende da escala, do orçamento e da infraestrutura. Analisaremos três dos nomes mais proeminentes.
1. Pinecone: O Gigante Gerenciado (Cloud-Native)
Pinecone é conhecido por ser um serviço totalmente gerenciado, focado na facilidade de escalabilidade e alta performance em ambientes de produção. É ideal para quem quer focar na lógica da IA e não na infraestrutura.
Vantagens e Desvantagens do Pinecone
- Prós: Escalabilidade elástica, manutenção zero, excelente suporte para grandes volumes de dados.
- Contras: Custo pode ser mais elevado em comparação com soluções auto-hospedadas, dependência total do provedor de nuvem.
2. Weaviate: O Banco de Dados de Gráficos Vetoriais
Weaviate se destaca por ser um banco de dados vetorial nativo, que suporta não apenas vetores, mas também a estrutura de um banco de dados de grafos. Ele permite consultas complexas que unem busca semântica e relações estruturadas.
# Exemplo conceitual de como Weaviate une vetores e metadados
# SELECT * FROM classes WHERE vector_similarity(embedding, $query_vector) > 0.8 AND author = 'Gabriel Kemmer'
Na minha experiência, Weaviate é robusto para sistemas onde os metadados são tão importantes quanto a similaridade vetorial. Ele pode ser auto-hospedado ou usado como serviço gerenciado.
3. ChromaDB: O Leve e Open Source
ChromaDB ganhou popularidade rapidamente por ser leve, fácil de integrar e totalmente open source. Muitas vezes, ele é usado como um banco de dados embarcado (in-memory) ou local para prototipagem e desenvolvimento inicial, embora suporte escalabilidade para produção.
Quando usar ChromaDB?
- Projetos de desenvolvimento local e testes rápidos.
- Aplicações de nicho com requisitos de infraestrutura mínima.
- Quando a privacidade dos dados exige que a base de dados fique totalmente sob seu controle em uma infraestrutura própria (como um servidor dedicado na Host You Secure).
Desafios Comuns na Implementação de Vector Databases
Embora poderosas, as Vector Databases apresentam desafios únicos que precisam ser gerenciados. Já vi clientes com problemas de performance por não considerarem estes pontos.
O Problema da Dimensionalidade do Embedding
Modelos mais novos geram vetores com mais dimensões (ex: 1536 ou mais). Isso aumenta a precisão semântica, mas a complexidade da busca (o custo computacional para calcular distâncias) cresce exponencialmente com o número de dimensões. É um trade-off direto entre precisão e latência/custo.
Métricas de Avaliação (Ground Truth)
Como saber se sua busca vetorial está realmente boa? A métrica padrão é a Precisão em K (Precision@K), que mede quantos dos $K$ resultados retornados são realmente relevantes para a consulta. É fundamental ter um conjunto de dados de teste com anotações humanas (o 'ground truth') para otimizar seus índices e seus modelos de embedding.
Erro Comum a Evitar: Não otimizar os parâmetros do índice ANN (como o fator de construção do grafo HNSW). Um índice mal configurado pode retornar resultados irrelevantes rapidamente, ou ser lento demais tentando ser perfeito. Sempre teste diferentes configurações de índices!
Integração e Orquestração com Frameworks
Para quem trabalha com Python, frameworks como LangChain e LlamaIndex simplificam drasticamente a orquestração entre LLMs, a ingestão de dados, a vetorização e a comunicação com o banco de dados vetorial. Esses frameworks atuam como a cola que une as peças do seu sistema RAG.
| Banco de Dados | Modelo de Serviço | Melhor Cenário | Curva de Aprendizado |
|---|---|---|---|
| Pinecone | Gerenciado (SaaS) | Produção de alta escala, rapidez no deploy | Baixa |
| Weaviate | Auto-Hospedado ou Gerenciado | RAG complexo com relações estruturadas (Grafos) | Média |
| ChromaDB | Embeddable/Local/Auto-Hospedado | Prototipagem, projetos pequenos/médios | Baixa/Média |
Otimizando a Infraestrutura para Performance Vetorial
Independentemente da Vector Database escolhida, a performance da infraestrutura subjacente é vital, especialmente se você optar por auto-hospedar Weaviate ou ChromaDB em modo servidor.
Escolha da Hospedagem VPS e Memória
Bancos de dados vetoriais dependem fortemente da memória RAM. Os índices vetoriais, especialmente aqueles construídos com HNSW, precisam ser carregados e acessados rapidamente. Um VPS com RAM insuficiente resultará em frequentes acessos ao disco (swap), o que destrói a baixa latência que buscamos.
Na Host You Secure, recomendo sempre alocar mais RAM do que o mínimo esperado, pois ela é usada para cache de índices e execução rápida das operações vetoriais. Para aplicações críticas, CPUs com bom desempenho single-thread também auxiliam na construção e atualização dos índices.
Monitoramento e Escalabilidade
Monitore métricas específicas como tempo de resposta da consulta ANN e taxa de acertos (recall). Se o tempo de resposta aumentar, pode ser sinal de que seu índice precisa ser reconstruído ou que você atingiu o limite de escalabilidade vertical do seu servidor. Se isso ocorrer, explore a migração para soluções gerenciadas ou utilize orquestradores de containers (Kubernetes) sobre nossa infraestrutura para escalabilidade horizontal.
Conclusão e Próximos Passos
Vector Databases não são apenas uma moda passageira; eles são a fundação sobre a qual a próxima geração de sistemas de busca e interação com IA está sendo construída. Dominar o conceito de embeddings e a arquitetura RAG, utilizando ferramentas como Pinecone, Weaviate ou ChromaDB, é um diferencial competitivo enorme hoje.
Se você está pronto para levar suas aplicações de IA além da pesquisa por palavras-chave e implementar buscas verdadeiramente semânticas, o primeiro passo é garantir uma infraestrutura estável e performática. Não deixe que a infraestrutura limite o potencial da sua IA. Para consultoria especializada em implementação RAG e infraestrutura robusta, entre em contato com a equipe da Host You Secure. Quer explorar mais sobre orquestração de IA? Visite nosso blog para mais artigos técnicos.
Leia também: Veja mais tutoriais de N8N
Comentários (0)
Ainda não há comentários. Seja o primeiro!