Vector Databases: O Guia Essencial para IA e Busca Semântica
Se você está mergulhando no mundo da Inteligência Artificial generativa, certamente já se deparou com o desafio de fazer com que Modelos de Linguagem Grandes (LLMs) usem informações externas com precisão. A resposta para escalar e contextualizar LLMs reside nas Vector Databases. Estes sistemas são a espinha dorsal da busca semântica moderna e das arquiteturas RAG (Retrieval-Augmented Generation). Como especialista em infraestrutura cloud e automação na Host You Secure, já implementei diversas soluções que dependem da eficiência dessas bases. Neste guia aprofundado, desvendaremos o que são, como funcionam e quais as melhores opções do mercado.
Nota Rápida: Na minha experiência, Vector Databases resolvem o problema de alucinação dos LLMs, fornecendo a eles um contexto factual e atualizado. Um estudo recente mostrou que a adoção de RAG com bases vetoriais pode reduzir as taxas de alucinação em mais de 60% em tarefas específicas de domínio.
O Que São Embeddings e Por Que Eles Mudaram a Busca?
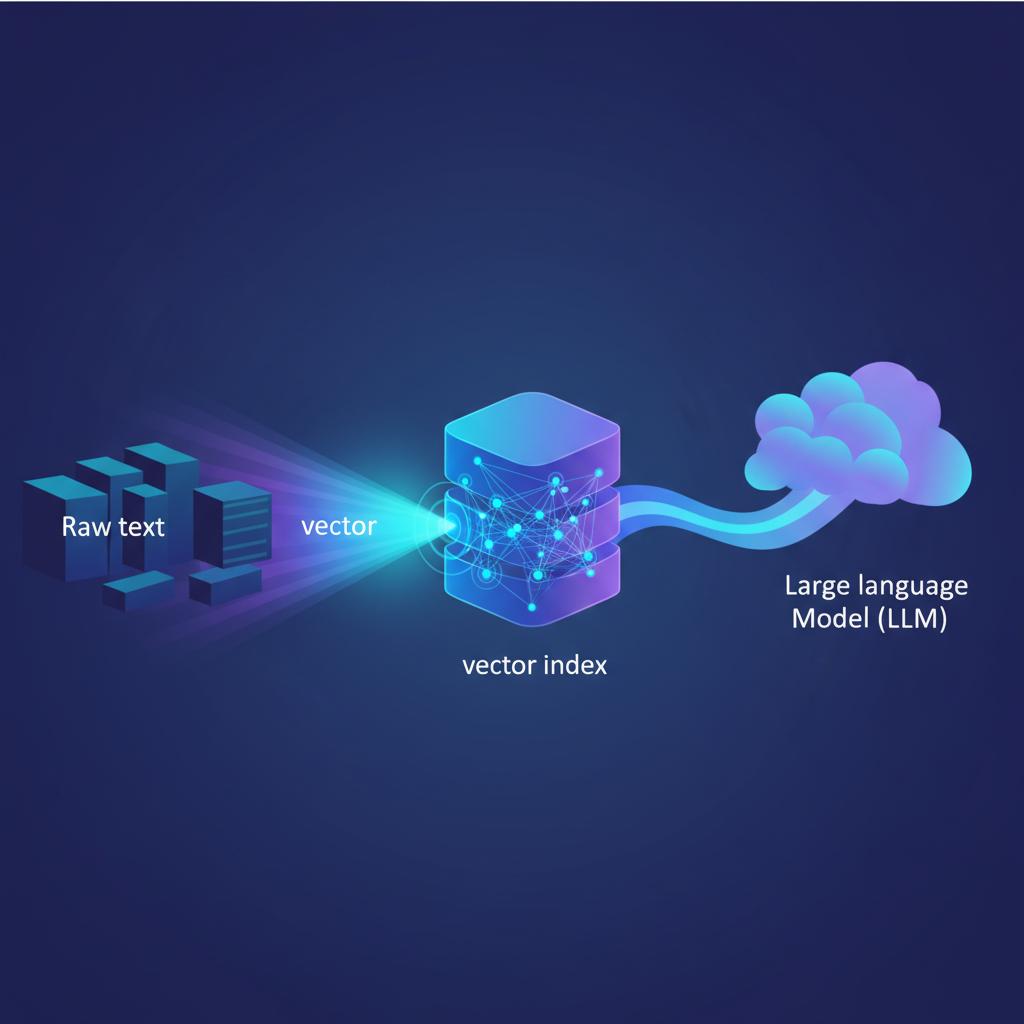
Antes de entender o banco de dados, precisamos entender o dado que ele armazena. Um embedding é, essencialmente, um vetor numérico multidimensional que representa o significado semântico de um pedaço de informação. Pense nele como coordenadas em um espaço onde itens com significados semelhantes estão mais próximos uns dos outros.
A Transformação da Busca: Da Palavra-Chave ao Significado
Sistemas de busca tradicionais (como os baseados em SQL ou ElasticSearch com BM25) funcionam por correspondência exata de palavras-chave. Se você busca por "carro veloz", ele busca documentos que contenham essas exatas palavras. Um sistema baseado em vetores, após converter sua busca em um vetor, procura por vetores vizinhos que representem o mesmo conceito. Assim, a busca por "carro veloz" pode retornar documentos que falam sobre "automóvel ágil" ou "veículo de alta performance", mesmo que as palavras exatas não estejam presentes.
- Geração de Embeddings: O processo começa com um Modelo de Embedding (como BERT, Word2Vec ou modelos da OpenAI) que transforma texto, imagens ou áudio em um vetor de alta dimensão (tipicamente entre 384 e 1536 dimensões).
- Indexação: O vetor gerado é armazenado no Vector Database.
- Consulta: A consulta do usuário é transformada em um vetor e o banco de dados utiliza algoritmos de vizinho mais próximo (como HNSW) para encontrar os vetores mais próximos no espaço vetorial.
Como a Similaridade Vetorial é Calculada
O cerne da operação é a métrica de similaridade. Geralmente, utilizamos a Similaridade de Cosseno. Este cálculo mede o ângulo entre dois vetores no espaço multidimensional. Um ângulo próximo de zero (cosseno próximo de 1) indica alta similaridade semântica.
# Pseudocódigo de Similaridade de Cosseno
Sim(A, B) = (A ⋅ B) / (||A|| * ||B||)
Dica de Insider: Em ambientes de produção com alta latência, é crucial otimizar a escolha do índice de vizinho mais próximo (ANN - Approximate Nearest Neighbor). Algoritmos como HNSW (Hierarchical Navigable Small Worlds) oferecem um trade-off excelente entre precisão e velocidade de consulta, sendo o padrão de mercado.
Arquiteturas RAG: O Papel Central dos Vector Databases
O grande boom dos Vector Databases está intrinsecamente ligado ao RAG (Retrieval-Augmented Generation). RAG permite que LLMs acessem dados proprietários, específicos ou atualizados sem a necessidade de retreinamento custoso.
Funcionamento de um Pipeline RAG
O fluxo de RAG é elegante e depende totalmente da capacidade de recuperação rápida da base vetorial. Eu já ajudei clientes a montarem pipelines onde a resposta dependia da busca em milhares de documentos técnicos em minutos.
- Indexação Inicial: Seus documentos são divididos em *chunks* (pedaços), convertidos em embeddings e armazenados no seu Vector Database (ex: Pinecone).
- Recebimento da Query: O usuário faz uma pergunta.
- Vetorização da Query: A pergunta é transformada em um vetor usando o mesmo modelo de embedding usado na indexação.
- Busca no DB: O vetor da query é enviado ao Vector Database, que retorna os N *chunks* de documentos mais semanticamente relevantes.
- Contextualização do LLM: Estes chunks recuperados são injetados no prompt do LLM como contexto (junto com a pergunta original).
- Geração da Resposta: O LLM gera uma resposta baseada nas fontes fornecidas.
Por Que Não Usar Bancos Tradicionais para RAG?
Bancos de dados relacionais (SQL) ou mesmo NoSQL tradicionais não são otimizados para a busca de similaridade vetorial em alta dimensão. Tentar realizar consultas vetoriais com milhões de registros em um PostgreSQL padrão, mesmo com extensões como pgvector, resultará em latências proibitivas em escala. A otimização de índices vetoriais é especializada; Vector Databases são construídos do zero para isso.
Comparativo: Pinecone, Weaviate e ChromaDB
A escolha da plataforma correta depende da sua necessidade de escala, infraestrutura e complexidade do dado. Na Host You Secure, recomendamos a solução mais adequada ao perfil do cliente. Aqui está uma visão geral das três soluções mais proeminentes:
| Banco de Dados | Foco Principal | Gerenciamento | Ideal Para |
|---|---|---|---|
| Pinecone | Escala e Performance em Nuvem (SaaS) | Totalmente Gerenciado (PaaS) | Grandes empresas, alta disponibilidade e baixa latência garantida. |
| Weaviate | Flexibilidade e Arquitetura Híbrida | Self-hosted ou Gerenciado | Projetos que precisam de filtragem complexa e modelos de ML integrados. |
| ChromaDB | Simplicidade e Desenvolvimento Local | Open Source, Embutido/Self-hosted | Prototipagem rápida, projetos menores ou rodando diretamente em ambientes como notebooks Python. |
Pinecone: Performance em Escala
Pinecone é uma solução puramente SaaS, focada em abstrair a complexidade da infraestrutura. Ele é conhecido por sua facilidade de uso e performance consistente em bilhões de vetores. Sua grande vantagem é o gerenciamento total. No entanto, isso significa um custo operacional que pode ser mais elevado em comparação com soluções self-hosted.
Weaviate: Poder de Filtragem Híbrida
Weaviate brilha na capacidade de combinar a busca vetorial com filtragem de metadados tradicional. Você pode executar uma consulta para "todos os documentos sobre LLMs que foram publicados após 2023 e são da autoria de Gabriel Kemmer". Essa capacidade híbrida é algo que eu considero essencial para sistemas de busca corporativa. Ele pode ser hospedado em sua própria infraestrutura, o que pode ser mais econômico se você já utiliza servidores VPS otimizados, como os que oferecemos. Se você busca infraestrutura robusta para hospedar suas aplicações, confira nossas opções de hospedagem VPS no Brasil.
ChromaDB: O Ponto de Partida Open Source
ChromaDB é excelente para começar. Ele se integra facilmente a ambientes Python e pode rodar embutido no seu processo de aplicação. Embora não seja a primeira escolha para um sistema que precise suportar milhões de QPS (Queries Per Second) com baixa latência, ele é imbatível em termos de barreira de entrada para experimentação com RAG.
Desafios e Melhores Práticas na Implementação
Implementar uma arquitetura baseada em vetores não é isenta de armadilhas. A experiência prática nos ensinou a antecipar problemas comuns.
Erro Comum 1: O Desalinhamento dos Embeddings
Este é o erro mais crucial. Se você usar o modelo de embedding X (ex: `text-embedding-ada-002` da OpenAI) para indexar seus dados e o modelo Y (ex: um modelo local Sentence Transformers) para vetorizar a query, os vetores não estarão no mesmo espaço semântico e a busca falhará miseravelmente. A regra de ouro é: Use exatamente o mesmo modelo de embedding para indexar e para consultar.
Otimização da Chunking Strategy (Estratégia de Fragmentação)
Como você divide seus documentos grandes em *chunks* afeta diretamente a qualidade da recuperação. Se o pedaço for muito pequeno, ele perde contexto; se for muito grande, a poluição semântica pode confundir o modelo. Já ajudei clientes a ajustarem essa estratégia, descobrindo que um tamanho de chunk entre 256 e 512 tokens, com uma sobreposição de 10% (overlap), geralmente oferece o melhor equilíbrio. Para dados estruturados ou código, abordagens baseadas em estrutura (como separação por função em código) são melhores que tamanhos fixos.
Gerenciamento de Metadados e Filtragem
Um erro que vejo frequentemente é indexar apenas o vetor e o texto. Os metadados (data, autor, categoria, ID da sessão) são cruciais para filtrar a busca antes da consulta vetorial, economizando tempo de processamento e melhorando a precisão. Sempre utilize a capacidade de filtragem do seu banco vetorial (especialmente no Weaviate ou Pinecone) para restringir o escopo da busca ANN.
A Escalabilidade da Infraestrutura para Vector Databases
Vector Databases, especialmente aqueles que você hospeda (self-hosted), são intensivos em memória e CPU, devido à complexidade dos cálculos de distância e à necessidade de manter os índices HNSW na RAM para velocidade. Isso nos leva à infraestrutura necessária.
VPS vs. Cloud Dedicado para Cargas de Trabalho Vetoriais
Para cargas de trabalho de RAG moderadas, um VPS robusto com boa quantidade de RAM (32GB+) pode ser suficiente para hospedar instâncias menores de ChromaDB ou Weaviate. No entanto, ao escalar para milhões de vetores e buscas em tempo real, você precisa de infraestrutura especializada.
Na Host You Secure, focamos em otimizar a performance de I/O e RAM para garantir que seus índices vetoriais carreguem rapidamente. Muitos clientes que migram de soluções mal dimensionadas para nossos VPS otimizados relatam ganhos significativos de latência. Se o seu projeto de IA exige estabilidade, considere migrar para uma infraestrutura dedicada aqui.
O Futuro: Bases Vetoriais Híbridas
A tendência clara é a convergência. Bancos de dados tradicionais estão adicionando funcionalidades vetoriais (como pgvector no PostgreSQL), e os bancos vetoriais estão aprimorando suas capacidades de filtragem de metadados (como Weaviate). A decisão futura não será se você usa um Vector DB, mas sim se você usa um DB híbrido (SQL + Vetor) ou um DB nativo vetorial otimizado para escala.
Conclusão e Próximos Passos
Vector Databases não são mais um luxo, mas sim uma necessidade fundamental para qualquer aplicação séria de IA que precise de conhecimento externo e contextualizado. Dominar o fluxo de embeddings, entender as diferenças entre Pinecone, Weaviate e ChromaDB, e aplicar a estratégia correta de RAG definirá o sucesso do seu projeto de IA. Lembre-se da importância da consistência dos modelos de embedding e da otimização dos seus *chunks*.
Se você está pronto para implementar uma arquitetura de IA robusta, escalável e sem alucinações, comece escolhendo a ferramenta certa para o seu nível de maturidade. Para tutoriais mais avançados sobre automação e integração de APIs, visite nosso blog e descubra como podemos ajudar você a construir o futuro da sua infraestrutura.
Leia também: Veja mais tutoriais de N8N
Comentários (0)
Ainda não há comentários. Seja o primeiro!