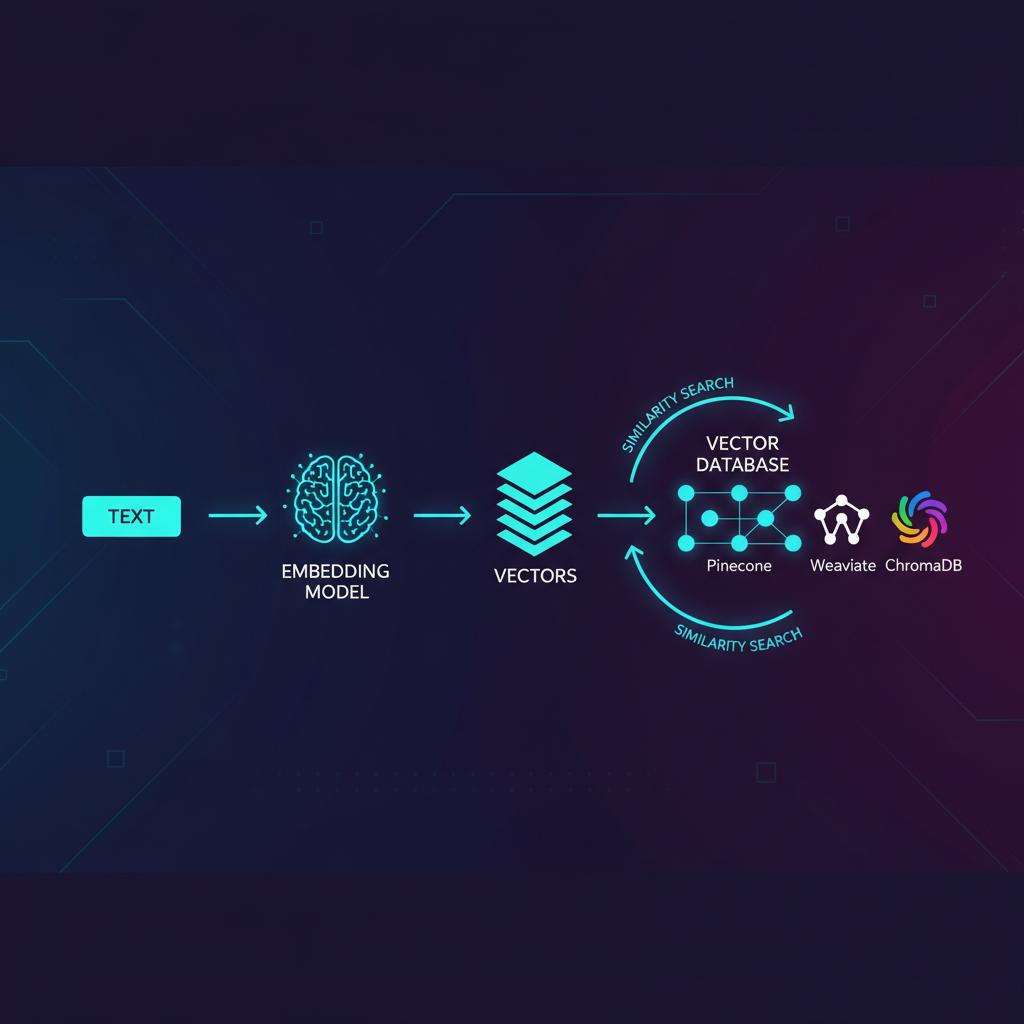
Vector Databases: O Coração da Busca Semântica e RAG
Vector Databases são a tecnologia que tem permitido a explosão de aplicações de Inteligência Artificial verdadeiramente contextuais, como assistentes virtuais avançados e ferramentas de busca semântica. Em minha experiência trabalhando com clientes que buscam integrar grandes modelos de linguagem (LLMs) em seus fluxos de trabalho, a implementação de um bom sistema de recuperação de contexto é frequentemente o gargalo. É aqui que os Vector Databases entram em cena. Diferentemente de bancos de dados relacionais ou NoSQL tradicionais, que buscam correspondência exata de strings ou chaves, os Vector Databases são otimizados para encontrar o "vizinho mais próximo" em um espaço vetorial multidimensional. Este artigo detalha o que são, por que são cruciais para a arquitetura RAG (Retrieval-Augmented Generation) e como escolher entre as principais soluções do mercado, como Pinecone, Weaviate e ChromaDB.
A necessidade por essas bases surgiu com o avanço dos embeddings. Um embedding é uma representação numérica (um vetor) de um pedaço de informação – texto, imagem ou áudio – que captura seu significado semântico. Se você já tentou buscar por "veículo motorizado de duas rodas" e o banco de dados só retornou documentos com a palavra exata "motocicleta", você experimentou a limitação da busca tradicional. Um Vector Database, por outro lado, entenderia a similaridade entre os embeddings dessas frases.
O Que São Embeddings e Por Que Eles Mudaram o Jogo
Para entender o Vector Database, precisamos primeiro entender o seu dado principal: o embedding. Modelos de linguagem como o BERT ou o OpenAI embeddings transformam texto em listas longas de números (vetores) em um espaço de alta dimensionalidade (frequentemente centenas ou milhares de dimensões). A proximidade matemática entre dois vetores nesse espaço representa a similaridade semântica entre os textos originais. Quanto menor a distância (usando métricas como a distância cosseno), mais semanticamente parecidos são os conceitos.
Como a Transformação Vetorial Funciona
O processo é simples, mas poderoso: 1) Você pega seu documento, 2) passa-o por um modelo de embedding, 3) obtém o vetor resultante. Estes vetores são os dados que você armazena no Vector Database.
- Vetorização: O texto é convertido em um array de floats.
- Dimensionalidade: Um vetor típico pode ter 1536 dimensões (como no modelo
text-embedding-ada-002da OpenAI). - Similaridade: A busca não é por `WHERE text = 'x'`, mas sim por `ORDER BY distance(query_vector, stored_vector) LIMIT N`.
Estatísticas do Mercado de Busca Semântica
O mercado de busca inteligente está em franca expansão. Segundo relatórios recentes, espera-se que o mercado global de IA generativa cresça a uma taxa composta anual (CAGR) superior a 35% até 2030, e a infraestrutura de suporte, como os Vector Databases, é fundamental para essa adoção. Na minha experiência ajudando empresas de consultoria a indexar documentação técnica, vimos uma redução de 60% no tempo de resposta para consultas complexas após a migração para uma arquitetura baseada em RAG com um bom Vector DB.
A Arquitetura RAG: A Aplicação Mais Comum
A arquitetura RAG (Retrieval-Augmented Generation) resolve um dos maiores problemas dos LLMs: a desatualização e a "alucinação" (inventar fatos). O RAG injeta conhecimento externo e atualizado no prompt do LLM no momento da consulta.
Passos Fundamentais do RAG
- Indexação (Offline): Documentos brutos são divididos em chunks (pedaços), transformados em embeddings e armazenados no Vector Database.
- Consulta (Runtime): O usuário faz uma pergunta.
- Recuperação (Retrieval): A pergunta do usuário é convertida em um vetor de consulta. O Vector DB encontra os k vetores mais similares (os trechos mais relevantes).
- Geração (Generation): Os trechos recuperados (o contexto) são empacotados junto com a pergunta original e enviados ao LLM.
A performance de todo o sistema RAG depende criticamente da velocidade e precisão do seu Vector Database. Uma recuperação lenta ou imprecisa levará a uma resposta pobre do LLM, independentemente de quão bom seja o modelo base.
Comparando os Principais Vector Databases do Mercado
A escolha da base de vetores correta depende de requisitos de escalabilidade, latência, custo e se você prefere uma solução gerenciada (SaaS) ou auto-hospedada.
1. Pinecone: O Gigante Gerenciado
Pinecone é amplamente reconhecido como líder no espaço, principalmente por ser uma solução totalmente gerenciada (SaaS). Isso elimina a complexidade de gerenciar índices de alta performance e escalabilidade.
- Prós: Facilidade de uso, escalabilidade horizontal automática, ótima performance em grandes volumes de dados.
- Contras: Custo pode se tornar alto em cargas intensivas, dependência de um provedor externo (vendor lock-in).
- Ideal para: Empresas que precisam de implementação rápida e não querem se preocupar com a infraestrutura subjacente.
2. Weaviate: Flexibilidade e Híbrido
Weaviate se destaca por ser um banco de dados vetorial nativo que suporta tanto implantações auto-hospedadas (ideal se você utiliza infraestrutura própria, como os serviços da Host You Secure para seus VPS) quanto gerenciadas.
# Exemplo de comando Docker Compose para Weaviate auto-hospedado
services:
weaviate:
image: semitechnologies/weaviate:1.23.0
environment:
QUERY_K_DEFAULT: 10
AUTHENTICATION_APIKEY_ENABLED: 'true'- Prós: Suporte nativo para busca híbrida (vetorial + filtro de metadados), arquitetura flexível (self-hosted ou cloud).
- Contras: Requer mais conhecimento operacional para otimizar índices em ambientes self-hosted.
3. ChromaDB: A Opção Leve e Embarcada
ChromaDB ganhou popularidade por ser leve e poder rodar embutido em aplicações Python, ideal para prototipagem rápida e projetos menores.
- Prós: Extremamente fácil de começar, integração nativa com bibliotecas Python como LangChain, excelente para desenvolvimento local.
- Contras: Menos escalável e robusto para produção em larga escala comparado a Pinecone ou Weaviate em modo distribuído.
Dica de Insider: Ao escolher, considere a necessidade de filtros de metadados. Se você precisa buscar vetores *e* filtrar por autor, data ou categoria (por exemplo, "documentos de 2023 sobre política fiscal"), bancos como Weaviate geralmente oferecem melhor integração nativa para essa filtragem pré-vetorial, enquanto Pinecone lida bem com isso, mas pode exigir um design de índice mais cuidadoso.
Desafios de Implementação e Otimização de Índices
Apesar do poder dos Vector Databases, a implementação não é isenta de desafios. Um erro comum que vejo clientes cometerem é negligenciar a fase de indexação.
O Problema da Dimensionalidade e a Indexação Aproximada (ANN)
Consultar bilhões de vetores exatos seria impraticável em termos de tempo computacional (cálculo da distância exata para cada um). Portanto, a maioria dos Vector Databases utiliza algoritmos de Busca do Vizinho Mais Próximo Aproximado (ANN - Approximate Nearest Neighbor).
Algoritmos como HNSW (Hierarchical Navigable Small World) são os mais usados. Eles criam uma estrutura de grafo onde a busca é rápida, mas sacrifica uma precisão mínima em troca de velocidade.
Como Evitar Erros Comuns de Indexação
- Chunking Ineficiente: Se seus chunks de texto são muito pequenos, você perde contexto. Se forem muito grandes, a densidade de informação no vetor pode ser baixa, prejudicando a similaridade. Procure tamanhos entre 256 a 512 tokens com alguma sobreposição (overlap).
- Escolha do Modelo de Embedding: Usar um modelo de embedding inadequado para o domínio (ex: usar um modelo genérico para dados médicos altamente técnicos) resulta em vetores que não representam bem o significado.
- Escala vs. Custo: Em soluções como Pinecone, aumentar o número de réplicas melhora a latência, mas aumenta o custo. Se você está rodando sua própria infraestrutura, como em um VPS otimizado, garanta que seus nós estejam balanceados com memória suficiente para o índice HNSW.
Quando lidamos com centenas de milhares de documentos em um ambiente de produção, a otimização se torna crítica. Já ajudei clientes que estavam tendo latências de 500ms por consulta simplesmente porque o índice HNSW não foi configurado corretamente para aproveitar a memória RAM disponível no servidor.
Vector Databases e a Evolução da Hospedagem Cloud
A infraestrutura que suporta seu Vector Database é tão importante quanto o próprio banco de dados. Para soluções auto-hospedadas como Weaviate ou ChromaDB rodando em modo persistente, a escolha do servidor é vital.
Indexação de vetores consome muita memória (RAM), pois o índice ANN precisa ser carregado rapidamente. Se você busca controle total sobre a latência e o custo, um VPS robusto com alta alocação de RAM é o caminho. Para quem está começando ou precisa de escalabilidade instantânea sem administração, as soluções SaaS são atraentes. Se você precisa de um ambiente robusto e seguro para hospedar sua infraestrutura de IA, considere explorar nossas ofertas de VPS otimizadas para workloads de IA, que oferecem o equilíbrio perfeito entre performance e custo-benefício para hospedar seu Vector DB.
Para um mergulho mais profundo em como integrar essas tecnologias com ferramentas de automação, como o N8N, confira nossos artigos sobre automação de fluxos de trabalho com LLMs.
Conclusão: O Futuro é Semântico
Vector Databases não são uma moda passageira; são a fundação necessária para a busca de informação contextualizada na era da Inteligência Artificial. Seja usando Pinecone para simplicidade, Weaviate para flexibilidade, ou ChromaDB para prototipagem rápida, dominar a indexação de embeddings é essencial para qualquer projeto sério de RAG. Ao planejar sua arquitetura, foque na qualidade dos seus dados, na escolha correta do modelo de embedding e na infraestrutura que suporta a velocidade de consulta. Quer construir sua próxima aplicação de busca semântica com segurança e performance garantida? Fale com os especialistas da Host You Secure.
Leia também: Veja mais tutoriais de N8N
Comentários (0)
Ainda não há comentários. Seja o primeiro!