Vector Databases: A Revolução da Busca Semântica em IA
Vector Databases são a espinha dorsal da inteligência artificial moderna, permitindo buscas baseadas em significado, não apenas palavras-chave. Este guia técnico, baseado em minha experiência com infraestrutura cloud e automação na Host You Secure, detalha como implementar soluções de busca semântica usando embeddings e frameworks RAG (Retrieval-Augmented Generation). A necessidade de processar dados não estruturados com precisão levou ao desenvolvimento dessas ferramentas, que revolucionaram a forma como as IAs interagem com o conhecimento.
Na minha experiência, muitas empresas migram de soluções tradicionais de Full-Text Search (como ElasticSearch) para Vector Databases quando a precisão contextual se torna primordial. É crucial entender que, enquanto bancos de dados relacionais ou NoSQL armazenam dados estruturados ou semiestruturados, os Vector Databases são otimizados para a operação matemática de similaridade de cosseno, que é o coração da busca vetorial.
O Conceito Fundamental: Embeddings e Vetorização
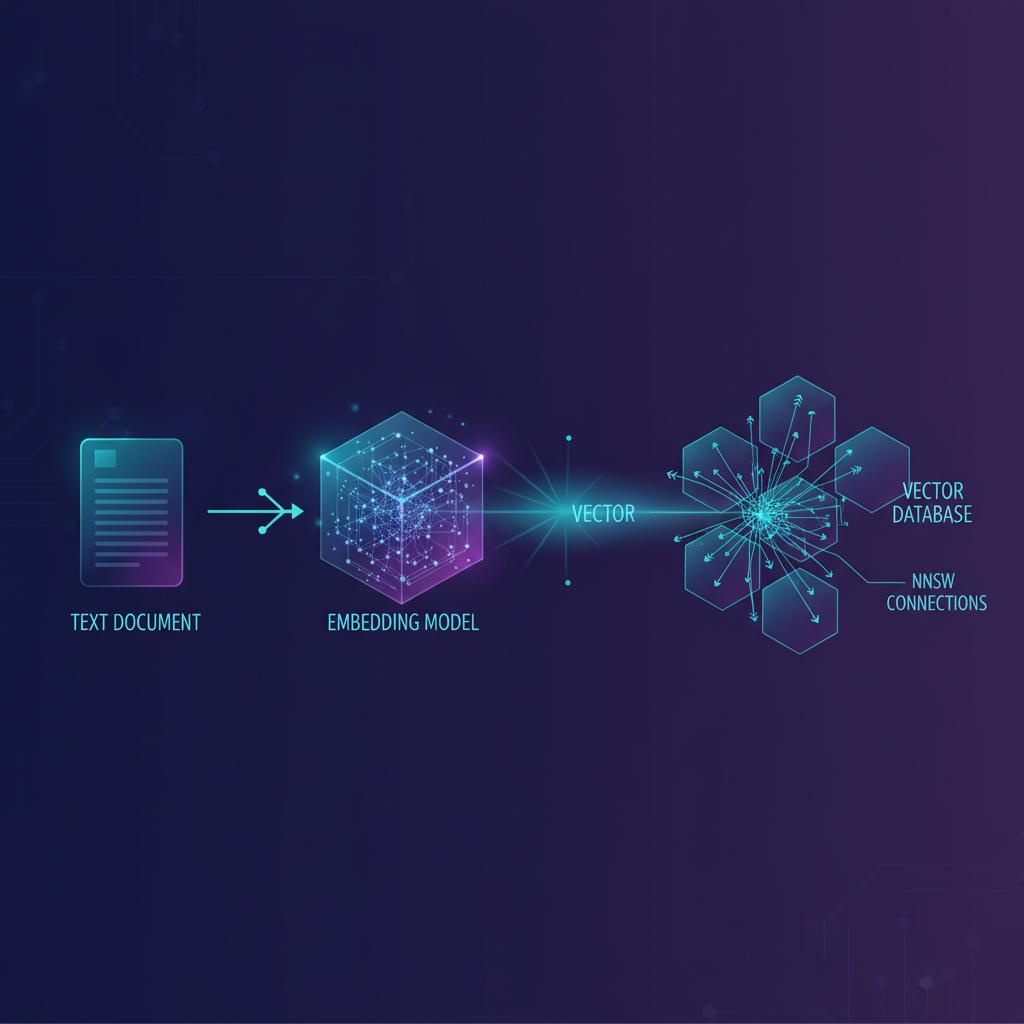
Antes de mergulharmos nas ferramentas, precisamos entender o que elas armazenam. Um embedding é uma representação numérica (um vetor de ponto flutuante) de um dado complexo, como texto, imagem ou áudio. Modelos de Machine Learning (como os LLMs) traduzem a semântica do dado em coordenadas em um espaço multidimensional. Dados com significados semelhantes ficam próximos nesse espaço vetorial.
Como os Embeddings Transformam Texto em Dados Consultáveis
O processo começa com um Modelo de Embedding. Se você tem a frase "O carro esportivo vermelho" e "O automóvel rápido carmesim", o modelo gera vetores que estarão muito próximos no espaço vetorial porque o significado é similar, mesmo que as palavras sejam diferentes. A dimensionalidade desses vetores pode variar de 128 até mais de 1536 dimensões, dependendo do modelo utilizado.
A capacidade de realizar cálculos rápidos nessas dimensões é o que diferencia um Vector Database de um banco de dados comum. Como dado técnico, a métrica de distância mais comum utilizada para determinar similaridade é a Distância Euclidiana ou o Cosseno de Similaridade. Entender isso é vital para otimizar a performance da sua infraestrutura.
Aplicações Práticas de Busca Vetorial
Já ajudei clientes a implementarem soluções onde a busca por similaridade é crítica:
- Sistemas de Recomendação: Se um usuário gosta do item A (vetorizado), o sistema encontra itens B, C e D cujos vetores são próximos ao vetor de A.
- Detecção de Duplicatas Semânticas: Encontrar artigos ou tickets de suporte que significam a mesma coisa, mesmo usando vocabulários diferentes.
- Chatbots Contextuais (RAG): Onde a pergunta do usuário é vetorizada para encontrar a informação mais relevante em uma base de conhecimento corporativa.
Introdução ao RAG: A Ponte entre LLMs e Dados Proprietários
O maior catalisador para o uso massivo de Vector Databases é o padrão RAG (Retrieval-Augmented Generation). LLMs (Large Language Models) como GPT-4 são poderosos, mas seu conhecimento é estático (limitado à data de treinamento) e eles não conhecem seus documentos internos. O RAG resolve isso.
O fluxo RAG envolve três passos essenciais:
- Indexing: Seus documentos são divididos em pedaços (chunks), vetorizados e armazenados no Vector Database.
- Retrieval: Quando o usuário faz uma pergunta, ela é vetorizada e usada para consultar o banco de vetores, recuperando os trechos de texto mais relevantes (os vizinhos mais próximos).
- Generation: Os trechos recuperados são injetados no prompt do LLM como contexto, permitindo que ele gere uma resposta precisa e baseada em seus dados.
Estatísticas de Mercado e Adoção
O crescimento da IA generativa impulsionou drasticamente a adoção dessas tecnologias. Segundo análises recentes, espera-se que o mercado global de bancos de dados vetoriais cresça a uma taxa composta anual (CAGR) superior a 30% até o final da década. Em 2023, vimos um aumento de 45% nas consultas de infraestrutura relacionadas à implementação de pipelines RAG.
O Desafio da Indexação em Escala
Um erro comum que vejo em implementações iniciais é subestimar o volume de dados. Indexar milhões de vetores rapidamente requer hardware robusto e otimização de índices. Para alta disponibilidade e baixa latência, você precisará de recursos de infraestrutura dedicados. Se você está buscando escalabilidade garantida para seus vetores, a escolha de uma VPS otimizada para processamento é crucial. Considere nossas soluções em comprar VPS no Brasil, projetadas para cargas de trabalho intensivas em computação.
Principais Vector Databases no Mercado
A escolha da ferramenta correta depende muito do seu caso de uso, orçamento e da necessidade de hospedagem gerenciada versus auto-hospedada. Apresento aqui as soluções que mais utilizamos e recomendamos.
Pinecone: O Gigante Gerenciado
Pinecone é amplamente conhecido por ser uma solução fully managed (totalmente gerenciada). Isso significa que você não precisa se preocupar com a infraestrutura subjacente, escalabilidade ou manutenção de índices complexos.
- Vantagens: Facilidade de uso, escalabilidade horizontal automática e excelente performance em tempo real.
- Desvantagens: Custo mais elevado em comparação com soluções auto-hospedadas e menor controle sobre o ambiente de execução.
Weaviate: Código Aberto e Extensível
Weaviate é um banco de dados vetorial nativo, open-source, que permite hospedar a solução em sua própria infraestrutura (on-premise ou em sua VPS). Ele é notável por suas capacidades de multi-modality e facilidade de integração com o ecossistema Python/AI.
Dica de Insider: Em implementações complexas, Weaviate permite que você defina esquemas de dados que combinam vetores com metadados tradicionais de forma muito eficiente, algo que o diferencia em cenários híbridos de busca.
ChromaDB: Leveza e Integração Python
ChromaDB ganhou popularidade rapidamente por ser extremamente leve e projetado para rodar em memória ou em modo cliente-servidor simples, sendo ideal para prototipagem e aplicações menores. Sua integração nativa com LangChain e LlamaIndex é um ponto forte.
Já vi muitos desenvolvedores começarem com ChromaDB para validar um MVP (Produto Mínimo Viável) antes de migrar para soluções mais robustas como Pinecone ou uma instalação auto-hospedada de Weaviate.
| Banco de Dados | Modelo de Serviço | Ideal Para | Complexidade de Setup |
|---|---|---|---|
| Pinecone | Gerenciado (SaaS) | Alta escala, velocidade de implantação | Baixa |
| Weaviate | Open Source / Gerenciado | Customização, busca híbrida, controle total | Média |
| ChromaDB | Open Source (Embeddable/Client) | Prototipagem, desenvolvimento local | Muito Baixa |
Otimização e Desafios na Implementação de Vector Stores
Configurar o banco de vetores é apenas metade da batalha. A otimização da infraestrutura e a manutenção da qualidade dos embeddings são cruciais para o sucesso do seu projeto de IA. A experiência prática mostra que a latência de busca é inversamente proporcional à taxa de acerto do seu modelo.
A Importância do HNSW (Hierarchical Navigable Small World)
A busca exata (brute-force) em milhões de vetores é proibitivamente lenta. Vector Databases utilizam algoritmos de Approximate Nearest Neighbor (ANN), sendo o HNSW o padrão ouro atual. HNSW constrói um grafo navegável que permite encontrar os vizinhos mais próximos muito rapidamente, sacrificando uma precisão mínima (tipicamente menos de 1%) em troca de latências de milissegundos.
Erro Comum a Evitar: Não otimizar os parâmetros HNSW (como M e efConstruction) para o seu conjunto de dados. Se você indexa 10 milhões de vetores e não ajusta esses parâmetros, sua latência de consulta pode ser inaceitável. Para otimização de infraestrutura, recomendamos usar máquinas com boa capacidade de memória RAM e I/O de disco rápido.
Gerenciamento de Metadados e Busca Híbrida
Muitas vezes, os usuários querem filtrar os resultados vetoriais com base em metadados tradicionais (ex: "Buscar documentos relevantes sobre o produto X, mas apenas aqueles publicados após 2024"). Isso é chamado de Busca Híbrida.
Na minha vivência, a melhor forma de lidar com isso é garantir que o Vector Database escolhido ofereça suporte robusto a filtragem de metadados pré-consulta. Se o filtro for muito restritivo, ele reduz o espaço de busca antes de calcular a similaridade vetorial, melhorando drasticamente a performance. Para esses cenários, Weaviate e Pinecone se destacam.
Escolhendo o Modelo de Embedding Correto
A qualidade do seu sistema RAG é diretamente limitada pela qualidade dos seus embeddings. Um dado de 2022, se indexado com um modelo treinado em 2021, pode ter representações vetoriais subótimas. Este é um ponto crítico que frequentemente negligenciamos.
Estatística de Referência: Modelos recentes como os da família BGE (BAAI General Embedding) ou OpenAI text-embedding-3-large demonstram melhor performance em benchmarks de similaridade comparados aos modelos legados, resultando em maior precisão RAG. Certifique-se de usar o modelo mais atualizado que caiba no seu orçamento de inferência.
Conclusão e Próximos Passos na Sua Jornada Vetorial
Vector Databases não são apenas uma moda; são uma necessidade fundamental para qualquer aplicação que dependa de compreensão semântica avançada de dados não estruturados. Dominar o uso de embeddings e integrá-los via RAG usando ferramentas como Pinecone, Weaviate ou ChromaDB é uma habilidade de alto valor no cenário atual da IA.
Se você está implementando um sistema RAG ou precisa hospedar sua própria infraestrutura de processamento vetorial com baixa latência e alta performance, a infraestrutura subjacente é o fator limitante. A Host You Secure está focada em fornecer a fundação de nuvem robusta que sua inteligência artificial merece. Se precisar de orientação técnica para escalar seu cluster vetorial ou automatizar o pipeline de ingestão de dados, confira nossos serviços ou explore mais artigos técnicos em nosso blog.
Leia também: Veja mais tutoriais de N8N
Comentários (0)
Ainda não há comentários. Seja o primeiro!