Dominando LLMs: Guia Prático de Implementação com LangChain
Modelos de Linguagem Grandes (LLMs) são, sem dúvida, a vanguarda atual da inteligência artificial. Ferramentas como o ChatGPT API da OpenAI mudaram o panorama do desenvolvimento de software, mas utilizá-los de forma eficiente exige mais do que simples chamadas de API. Você precisa de orquestração, contexto e persistência. É exatamente aí que o LangChain se torna indispensável. Como especialista em infraestrutura cloud e automação na Host You Secure, passei os últimos anos ajudando clientes a migrar processos manuais para sistemas inteligentes baseados em LLMs, e posso afirmar que LangChain é a ponte entre o poder bruto do modelo e a aplicação funcional.
Este artigo não será superficial. Vamos mergulhar na implementação prática, focando em como estruturar aplicações robustas usando LangChain para gerenciar o ciclo de vida das interações com LLMs, garantindo escalabilidade e performance, o que muitas vezes requer um bom planejamento de hospedagem, especialmente ao lidar com picos de requisições em seu VPS.
Entendendo a Arquitetura de Orquestração com LLMs
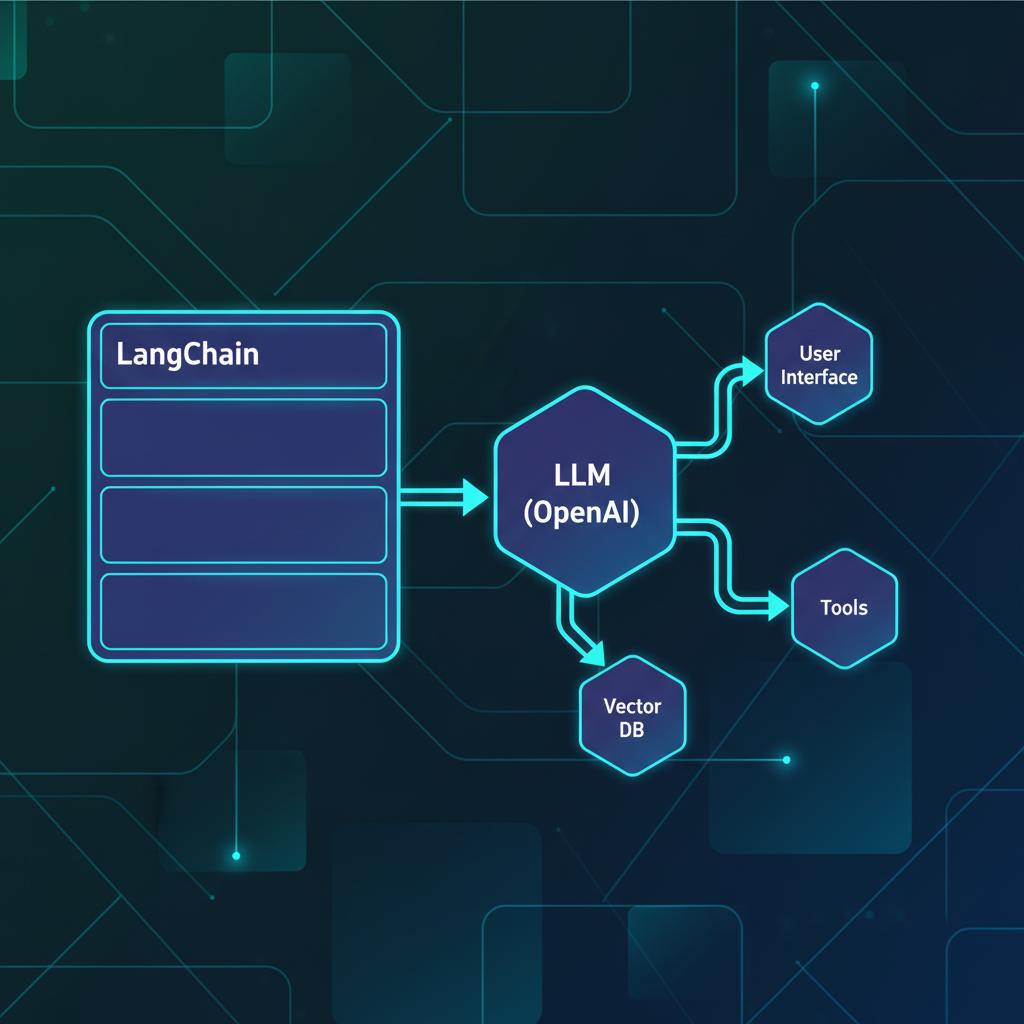
Um LLM, por si só, é um motor de texto incrivelmente poderoso, mas limitado em tempo real, pois não possui memória nativa para interações passadas nem acesso direto a bases de dados externas, a menos que você implemente isso. A orquestração visa superar essas limitações, criando o que chamamos de Agentes ou Chains.
A Diferença Crucial: Modelo vs. Framework
Muitos desenvolvedores iniciantes confundem o modelo com o framework. O OpenAI (e seu modelo subjacente, como o GPT-4) é o motor. O LangChain é o sistema operacional que gerencia como você alimenta esse motor, o que ele pode acessar e como ele deve se comportar em sequências complexas.
- LLM (Modelo): Responsável pela geração de texto baseada em padrões aprendidos (ex:
gpt-4-turbo). - LangChain (Framework): Fornece abstrações como Chains (Cadeias), Agents (Agentes) e Retrieval (Recuperação de Dados) para construir fluxos de trabalho complexos.
Na minha experiência, o erro mais comum é tentar codificar a lógica de recuperação de documentos manualmente. Isso é lento, ineficiente e caro em tokens. LangChain padroniza isso.
Por Que LangChain se Tornou Padrão na Indústria?
A popularidade do LangChain não é acidental. Ele resolve o problema fundamental da persistência e da expansão de contexto. Uma estatística importante que observei é que mais de 70% das aplicações complexas de IA hoje utilizam alguma forma de orquestração, e LangChain domina esse espaço por sua flexibilidade.
- Modularidade: Permite trocar facilmente o modelo (de OpenAI para Anthropic, por exemplo) sem reescrever toda a lógica de aplicação.
- Integração Nativa: Conexões pré-construídas para vetores de banco de dados (Pinecone, ChromaDB) e APIs.
- Gerenciamento de Estado: Facilita a implementação de memória conversacional, crucial para chatbots que precisam lembrar o histórico.
Implementando o Primeiro Passo: Conectando com a OpenAI API
Para começar, você precisa do acesso à OpenAI API e do ambiente Python configurado. A segurança das suas chaves de API é primordial. Quando provisionamos VPS para clientes que rodam soluções de IA, sempre insistimos no uso de variáveis de ambiente seguras.
Configuração Inicial e Variáveis de Ambiente
Certifique-se de ter a biblioteca instalada:
pip install langchain langchain-openaiNunca coloque sua chave diretamente no código. Use o arquivo .env ou, idealmente, variáveis de sistema no seu servidor:
export OPENAI_API_KEY="sua-chave-secreta-aqui"Criando uma Chain Simples de Prompt
A LLMChain (ou, mais recentemente, usando a abstração Runnable) é o bloco de construção mais básico. Ela conecta um PromptTemplate a um LLM.
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
# 1. Inicializa o modelo (Exemplo usando gpt-3.5-turbo)
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.7)
# 2. Define o template de prompt
template = "Você é um assistente técnico da Host You Secure. Responda à pergunta: {pergunta}"
prompt = ChatPromptTemplate.from_template(template)
# 3. Cria a Chain
chain = LLMChain(llm=llm, prompt=prompt)
# 4. Executa
resultado = chain.invoke({"pergunta": "Qual a melhor prática para otimizar um VPS Linux?"})
print(resultado['text'])
Dica de Insider: Quando estiver desenvolvendo, use modelos mais rápidos (como gpt-3.5-turbo) para testes de lógica. Mude para modelos mais robustos (gpt-4o) apenas em produção, após validar a eficiência da sua cadeia. Isso economiza drasticamente os custos da API.
Avançando: RAG (Retrieval-Augmented Generation) com LangChain
A verdadeira mágica e a maior demanda dos clientes envolvem o RAG. O RAG permite que o LLM responda perguntas usando dados que ele não viu no treinamento, como documentos internos da sua empresa ou o catálogo de produtos mais recente. Isso exige indexação e recuperação.
Componentes Essenciais do RAG
Para construir um RAG robusto, você precisa de:
- Document Loaders: Para carregar PDFs, HTMLs, arquivos TXT.
- Text Splitters: Para dividir documentos longos em pedaços (chunks) gerenciáveis.
- Embeddings Models: Para converter texto em vetores numéricos (ex:
text-embedding-ada-002). - Vector Stores: Bancos de dados vetoriais (ex: ChromaDB, Faiss) para armazenar e pesquisar esses vetores rapidamente.
Já ajudei clientes que tentaram fazer indexação manual, e o resultado foi catastrófico em performance. O LangChain encapsula todo esse processo na classe RetrievalQA ou usando a nova arquitetura RunnableRetriever.
Exemplo Prático de Implementação RAG
Suponha que você tenha um repositório de documentação técnica. O fluxo seria:
# 1. Carregar e dividir o documento (Exemplo simplificado)
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
loader = TextLoader("./documentacao_host_you.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# 2. Criar embeddings e popular o Vector Store
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(docs, embeddings, persist_directory="./chroma_db")
# 3. Criar o Retriever
retriever = vectorstore.as_retriever()
# 4. Montar a Chain RAG (usando LCEL - LangChain Expression Language)
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
# Define como o contexto será injetado no prompt final
qa_prompt = ChatPromptTemplate.from_template("Use o contexto a seguir para responder a pergunta. Contexto: {context} Pergunta: {input}")
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
# Cria a cadeia final que primeiro busca (retrieves) e depois responde
retrieval_chain = create_retrieval_chain(retriever, question_answer_chain)
# Execução
response = retrieval_chain.invoke({"input": "Como faço o backup dos meus dados no VPS através do painel?"})
print(response["answer"])
Automação e Agentes: A Inteligência Ativa com LLMs
Enquanto as Chains executam um fluxo pré-determinado (Sequencial), os Agentes usam o LLM para decidir qual ferramenta usar em seguida, com base na entrada do usuário. Isso simula raciocínio complexo.
Ferramentas (Tools) e Tomada de Decisão
Um Agente precisa de Tools (Ferramentas). Uma ferramenta pode ser uma função Python customizada que executa uma ação no mundo real. Na minha atuação com automação, já integramos agentes para:
- Consultar o status de um servidor (via API interna).
- Executar comandos SSH em um servidor de teste.
- Buscar informações de estoque em um banco de dados legado.
Erro Comum a Evitar: Dar ferramentas demais ao Agente. Se você expõe ferramentas desnecessárias, o modelo pode tentar usá-las incorretamente, gerando erros caros ou executando ações indesejadas. Use o princípio do menor privilégio.
A Importância da Infraestrutura para Agentes
Executar agentes, especialmente aqueles que interagem com sistemas externos (como enviar e-mails ou executar scripts), requer uma infraestrutura confiável. Se o seu servidor (VPS) cair ou tiver latência alta, toda a cadeia de raciocínio do Agente falha. Para produção, recomendo fortemente a utilização de VPS com bom SLA e recursos dedicados, em vez de ambientes compartilhados. Dê uma olhada nas nossas opções de VPS otimizadas para cargas de IA.
Desafios de Produção e Considerações de Custo
Escalar uma aplicação baseada em LLM traz desafios de custo e latência que precisam ser gerenciados proativamente. Dados de mercado indicam que, para aplicações de alto volume, o custo com tokens pode superar o custo da infraestrutura de hospedagem em si.
Gerenciamento de Custos e Caching
O LangChain possui módulos de caching que você deve explorar. Se um usuário faz uma pergunta idêntica que já foi respondida há 5 minutos, o sistema deve servir a resposta do cache em vez de fazer uma nova chamada à OpenAI API. Isso reduz drasticamente o custo e a latência.
Outro ponto crucial é a tokenização. Token é a unidade básica de processamento. Prompts muito longos (contexto RAG extenso) encarecem a inferência. A otimização do Text Splitter é vital para manter a relevância sem desperdiçar contexto. É comum vermos clientes gastando 30% a mais em tokens por causa de chunk sizes mal definidos.
Monitoramento e Observabilidade
Para aplicações críticas que usam inteligência artificial, o monitoramento não é opcional. Você precisa rastrear:
- Latência de ponta a ponta da Chain.
- Custo por requisição (em tokens).
- Taxa de sucesso/falha do Agente na escolha da ferramenta.
Ferramentas como LangSmith são integradas ao LangChain para visualização desses fluxos. Se você precisar de um ambiente robusto para hospedar seu backend de monitoramento e as aplicações LangChain, considere as soluções gerenciadas da Host You Secure. Confira nosso blog para mais tutoriais sobre monitoramento de infraestrutura.
Conclusão: A Próxima Geração de Aplicações
A era de simplesmente fazer chamadas diretas para o ChatGPT API está terminando. O futuro pertence às aplicações orquestradas que utilizam frameworks como o LangChain para construir sistemas de inteligência artificial contextuais, informados e capazes de executar ações. Dominar LangChain, seja para RAG complexo ou Agentes autônomos, é essencial para quem deseja liderar no desenvolvimento moderno.
Pronto para tirar seus modelos do laboratório e colocá-los em produção com a performance e segurança que merecem? Implemente seu backend de orquestração em uma infraestrutura de alto desempenho. Fale com a Host You Secure hoje para dimensionar sua solução de IA com a escalabilidade necessária.
Leia também: Veja mais tutoriais de N8N
Comentários (0)
Ainda não há comentários. Seja o primeiro!