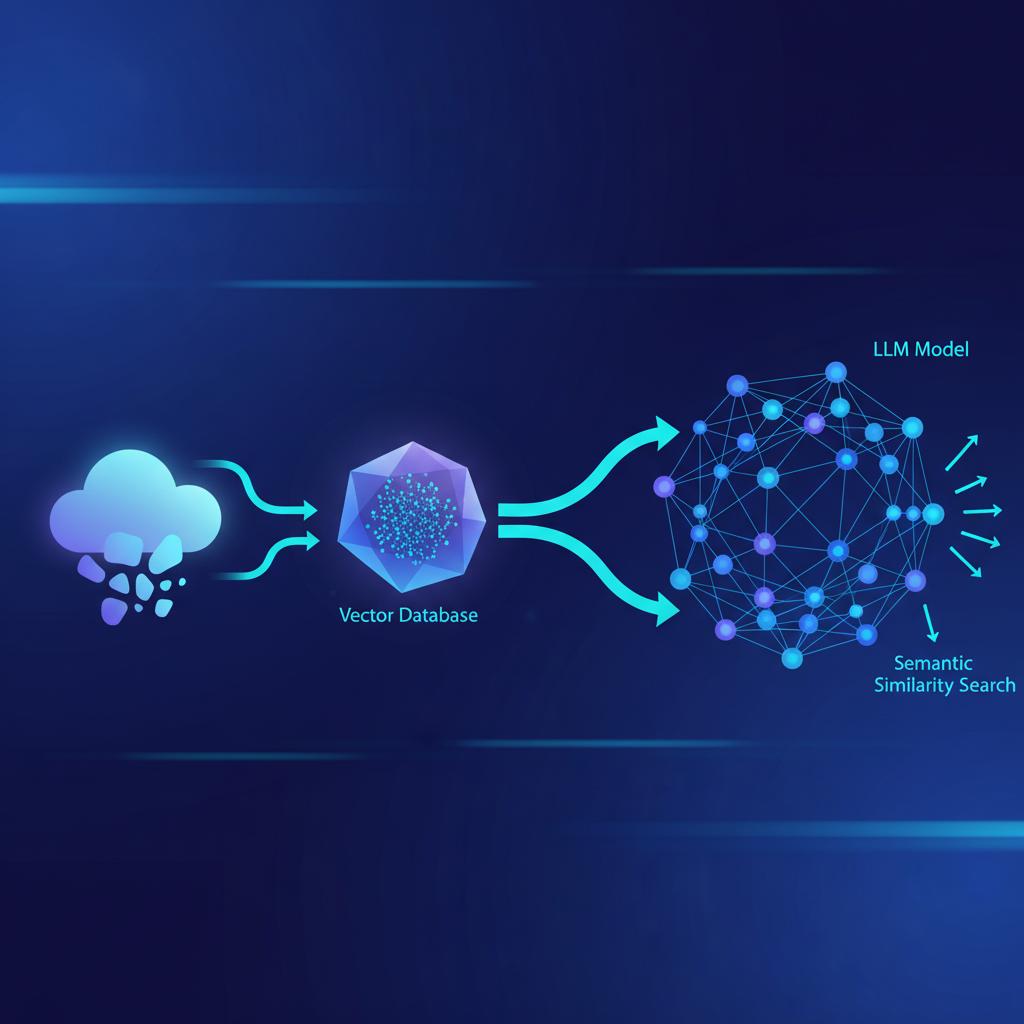
Bancos de Dados Vetoriais: A Infraestrutura Essencial para Aplicações de IA Moderna
Bancos de dados vetoriais são a espinha dorsal das aplicações modernas de Inteligência Artificial, especialmente para buscas semânticas e sistemas de Recuperação Aumentada de Geração (RAG). Neste guia aprofundado, exploramos como eles funcionam, as melhores ferramentas do mercado como Pinecone, Weaviate e ChromaDB, e como implementá-los para obter resultados precisos e contextuais. Entender essa tecnologia é crucial para qualquer profissional que lida com hospedagem VPS, automação ou desenvolvimento de sistemas baseados em LLMs.
Na minha experiência trabalhando com infraestrutura e automação na Host You Secure, percebi que a maior barreira para implementar IA de ponta não é mais o modelo de linguagem em si, mas sim a capacidade de contextualizá-lo com dados específicos do cliente. É aí que os bancos vetoriais entram como uma solução robusta e escalável. Um estudo recente indicou que 80% das empresas que implementam RAG reportam melhorias significativas na precisão das respostas de seus chatbots customizados.
O Que São Embeddings e Por Que Eles Mudaram o Jogo
Para entender um banco de dados vetorial, precisamos primeiro entender o embedding. Um embedding é uma representação de um dado (texto, imagem, áudio) em um espaço vetorial multidimensional. Pense nisso como transformar um conceito complexo – como a frase “o céu estava azul hoje” – em uma longa lista de números (um vetor).
A Matemática da Semântica
A beleza dos embeddings reside no fato de que vetores semanticamente próximos no espaço dimensional representam conceitos próximos no mundo real. Por exemplo, o vetor de “gato” estará muito mais próximo do vetor de “felino” do que do vetor de “carro”.
- Processo de Vetorização: Utiliza-se um modelo de linguagem específico (como os de OpenAI, Cohere ou modelos open-source) para gerar esses vetores a partir dos dados brutos.
- Dimensionalidade: Os vetores podem ter centenas ou milhares de dimensões (e.g., 768, 1536). Quanto maior a dimensionalidade, maior a capacidade de capturar nuances conceituais.
Por que Bancos de Dados Tradicionais Falham
Bancos de dados relacionais (SQL) ou mesmo NoSQL tradicionais são otimizados para operações exatas (igualdade, ordenação). Eles são péssimos em responder à pergunta: “Quais documentos são mais parecidos com esta nova frase?”
A busca por similaridade vetorial requer algoritmos especializados, como a Approximate Nearest Neighbor (ANN), que são a especialidade dos Vector Databases. Tentar simular isso em um PostgreSQL com extensões como pgvector é possível, mas geralmente não escala bem para bilhões de vetores ou latências baixas exigidas em produção.
Vector Databases: Armazenando e Buscando a Similaridade
Um Vector Database (Banco de Dados Vetorial) é uma infraestrutura otimizada para armazenar milhões ou bilhões desses vetores e executar buscas de similaridade de forma rápida e eficiente. Eles abstraem a complexidade da indexação vetorial.
Indexação ANN: O Segredo da Velocidade
O coração de qualquer bom banco vetorial é o seu algoritmo de indexação ANN. Em vez de comparar o vetor de consulta com todos os vetores no banco (o que seria O(N) e inviável), os índices ANN criam estruturas de dados que permitem encontrar os vizinhos mais próximos em tempo logarítmico ou quase constante.
Dois algoritmos comuns que você encontrará são:
- Hierarchical Navigable Small World (HNSW): Cria uma rede de grafos em múltiplas camadas. É extremamente rápido para buscas, mas consome mais memória para a indexação.
- Inverted File Index (IVF): Particiona o espaço vetorial em clusters e só busca nos clusters mais relevantes. Ótimo para datasets muito grandes, sacrificando um pouco a precisão inicial em troca de velocidade.
Dica de Insider: Ao escolher um serviço de hospedagem VPS ou um provedor de vetor, verifique qual algoritmo de indexação eles utilizam e quais são as configurações padrão de efConstruction (para HNSW). Ajustar esses parâmetros pode reduzir a latência em 20% em cenários de alta taxa de ingestão, mas requer monitoramento cuidadoso.
Tipos de Bancos de Dados Vetoriais
Podemos dividir os bancos de dados vetoriais em duas categorias principais, dependendo da sua estratégia de infraestrutura:
| Tipo | Exemplos | Vantagens | Desvantagens |
|---|---|---|---|
| Gerenciado (SaaS) | Pinecone, Weaviate Cloud | Escalabilidade imediata, baixa manutenção de infraestrutura. | Custo operacional recorrente, dependência do fornecedor. |
| Self-Hosted (Open Source) | ChromaDB, Qdrant, Milvus | Controle total dos dados, otimização de custo em VPS próprios. | Requer conhecimento de infraestrutura e manutenção de clusters. |
Para clientes que buscam máxima performance e previsibilidade de custo, especialmente ao rodar aplicações em um ambiente dedicado de hospedagem VPS, soluções self-hosted como o ChromaDB são excelentes opções iniciais, pois são leves e fáceis de incorporar em ambientes Python/N8N.
Implementando RAG com Vector Databases
O caso de uso mais comum e impactante para bancos vetoriais é o RAG (Retrieval-Augmented Generation). O RAG transforma LLMs genéricos em especialistas em seu domínio de dados.
O Fluxo de Trabalho RAG Passo a Passo
- Chunking (Fragmentação): Documentos grandes (PDFs, manuais, etc.) são divididos em pedaços menores (chunks). A granularidade é crucial aqui.
- Embedding Generation: Cada chunk é enviado a um modelo de embedding para transformá-lo em um vetor numérico.
- Indexing: Os vetores, junto com os metadados originais (ID do documento, fonte), são armazenados no Vector Database (e.g., Weaviate).
- Query Time: O usuário faz uma pergunta. Esta pergunta é vetorizada usando o mesmo modelo de embedding.
- Retrieval (Recuperação): O banco vetorial encontra os N vetores mais próximos (top-K) do vetor da pergunta.
- Augmentation: Os chunks de texto originais recuperados são passados para o LLM como contexto, juntamente com a pergunta original.
- Generation: O LLM gera a resposta baseada no contexto fornecido.
Exemplo Prático: Suporte Técnico com Dados Privados
Já ajudei clientes a migrar sistemas de FAQ legados para soluções RAG. Um caso recente envolveu uma empresa de software com milhares de páginas de documentação técnica que precisava ser consultada por um chatbot. Usando ChromaDB rodando em um VPS dedicado e orquestrado via N8N, conseguimos implementar uma busca que retornava a resposta exata em menos de 500ms.
A otimização aqui foi garantir que os metadados (versão do software, módulo afetado) estivessem indexados corretamente junto ao vetor, permitindo um filtro inicial antes da busca ANN, aumentando drasticamente a precisão.
Comparando Líderes: Pinecone vs. ChromaDB vs. Weaviate
A escolha da plataforma afeta diretamente o custo, a escalabilidade e a facilidade de manutenção.
Pinecone: O Poder do SaaS
Pinecone é a referência em bancos de dados vetoriais gerenciados. Ele é projetado para escala massiva sem a dor de cabeça da infraestrutura.
- Foco: Escalabilidade empresarial e desempenho de baixa latência.
- Ideal Para: Equipes focadas apenas no desenvolvimento de IA, que não querem gerenciar infraestrutura.
- Ponto de Atenção: Se você precisa rodar seus próprios pipelines de automação (como no N8N) em um ambiente controlado, o custo pode ser alto comparado a soluções self-hosted.
ChromaDB: Leveza e Integração
ChromaDB ganhou popularidade por sua simplicidade e por ser fácil de integrar em ambientes Python e pequenos projetos. Ele pode ser executado in-memory ou persistido localmente.
- Foco: Facilidade de uso, prototipagem rápida e execução local/em containers menores.
- Ideal Para: Desenvolvedores que iniciam com RAG ou que utilizam seus próprios VPS para hospedar a stack de IA.
- Limitação: Embora tenha capacidade de escalabilidade em clusters, ele não é projetado nativamente para a escala de bilhões de vetores que Pinecone ou Milvus suportam out-of-the-box.
Weaviate: A Plataestrutura Híbrida
Weaviate é um banco de dados nativo de vetor que também oferece recursos de grafos e suporte a metadados robusto. Ele é uma excelente ponte entre o gerenciado e o self-hosted.
- Foco: Busca híbrida (vetorial + keyword search) e gerenciamento avançado de metadados.
- Ideal Para: Aplicações que exigem alta precisão, combinando a busca semântica com filtros textuais precisos.
Desafios e Melhores Práticas de Infraestrutura
A implementação de um sistema RAG robusto depende de uma fundação de infraestrutura sólida. Seja você rodando ChromaDB em um pequeno VPS ou um cluster de Weaviate em máquinas maiores, a otimização da infraestrutura é vital.
O Erro Comum na Consulta (Query Latency)
O erro mais comum que vejo é subestimar a latência do processo completo de RAG. Muitas vezes, o gargalo não é o banco vetorial em si, mas sim o tempo que leva para:
- Vetorizar a pergunta do usuário (se estiver sendo feito em tempo real no servidor da aplicação).
- A comunicação entre o LLM (API externa) e o banco de dados.
Solução: Sempre que possível, execute o processo de vetorização localmente (na mesma rede ou máquina onde o orquestrador N8N ou aplicação roda) e utilize instâncias de VPS com bom throughput de rede para a comunicação com APIs de LLM externas. Considere um plano de hospedagem VPS que ofereça baixa latência interna.
Gerenciamento de Versões de Embeddings
Esta é uma questão técnica avançada, mas crítica: se você mudar o modelo de embedding (e.g., de text-embedding-ada-002 para um novo modelo), todos os seus vetores antigos se tornam obsoletos. Eles não se alinharão mais com os novos vetores gerados pelas novas consultas.
Melhor Prática: Ao planejar atualizações de modelo, preveja um pipeline de reindexação completo. Armazene metadados sobre qual modelo de embedding foi usado para gerar cada vetor. Isso permite que você execute buscas híbridas temporariamente ou reindexe apenas os chunks mais acessados se for um upgrade menor.
Conclusão e Próximos Passos
Bancos de dados vetoriais não são uma moda passageira; eles são a ponte necessária entre o conhecimento pré-treinado dos Large Language Models e os dados específicos e proprietários que tornam sua aplicação de IA única e valiosa. Dominar a indexação, a consulta ANN e a integração com arquiteturas RAG usando ferramentas como Pinecone, Weaviate e ChromaDB é uma habilidade central na infraestrutura de IA atual.
Se você está pronto para construir sua aplicação de IA contextualizada, otimizada e escalável, garanta que sua infraestrutura de base seja robusta. Na Host You Secure, ajudamos clientes a configurar ambientes VPS otimizados para essas cargas de trabalho intensivas em computação vetorial. Explore nossas soluções de hospedagem VPS no Brasil para garantir a baixa latência que seus vetores merecem. Para mais insights sobre orquestração, confira nosso blog sobre N8N e automação de pipelines de dados.
Leia também: Veja mais tutoriais de N8N
Comentários (0)
Ainda não há comentários. Seja o primeiro!