Bancos de Dados Vetoriais: A Chave para a Busca Semântica Moderna
Bancos de dados vetoriais são, sem dúvida, a tecnologia que está redefinindo a forma como interagimos com dados não estruturados em aplicações de Inteligência Artificial. Para quem trabalha com automação e infraestrutura, entender essa tecnologia é crucial, especialmente com o crescimento exponencial de modelos de linguagem grandes (LLMs). A principal função de um Vector Database é superar as limitações da busca tradicional baseada em palavras-chave, permitindo que sistemas compreendam a intenção e o contexto por trás das consultas. Neste artigo técnico, baseado na minha experiência com implementação de soluções complexas na Host You Secure, vamos mergulhar na arquitetura, nos principais players de mercado e nas aplicações práticas.
Em minha experiência, quando um cliente migra de um sistema de busca tradicional (como ElasticSearch ou MySQL com LIKE) para uma solução baseada em vetores, a melhoria na relevância dos resultados de busca pode ultrapassar 40%. Isso porque, em vez de procurar a string exata, procuramos a proximidade matemática no espaço vetorial. Em 2023, o mercado de bancos de dados vetoriais foi avaliado em centenas de milhões de dólares, com projeções de crescimento vertiginoso, impulsionado pela adoção de IA Generativa.
O Que São Embeddings e Por Que Eles São Essenciais?
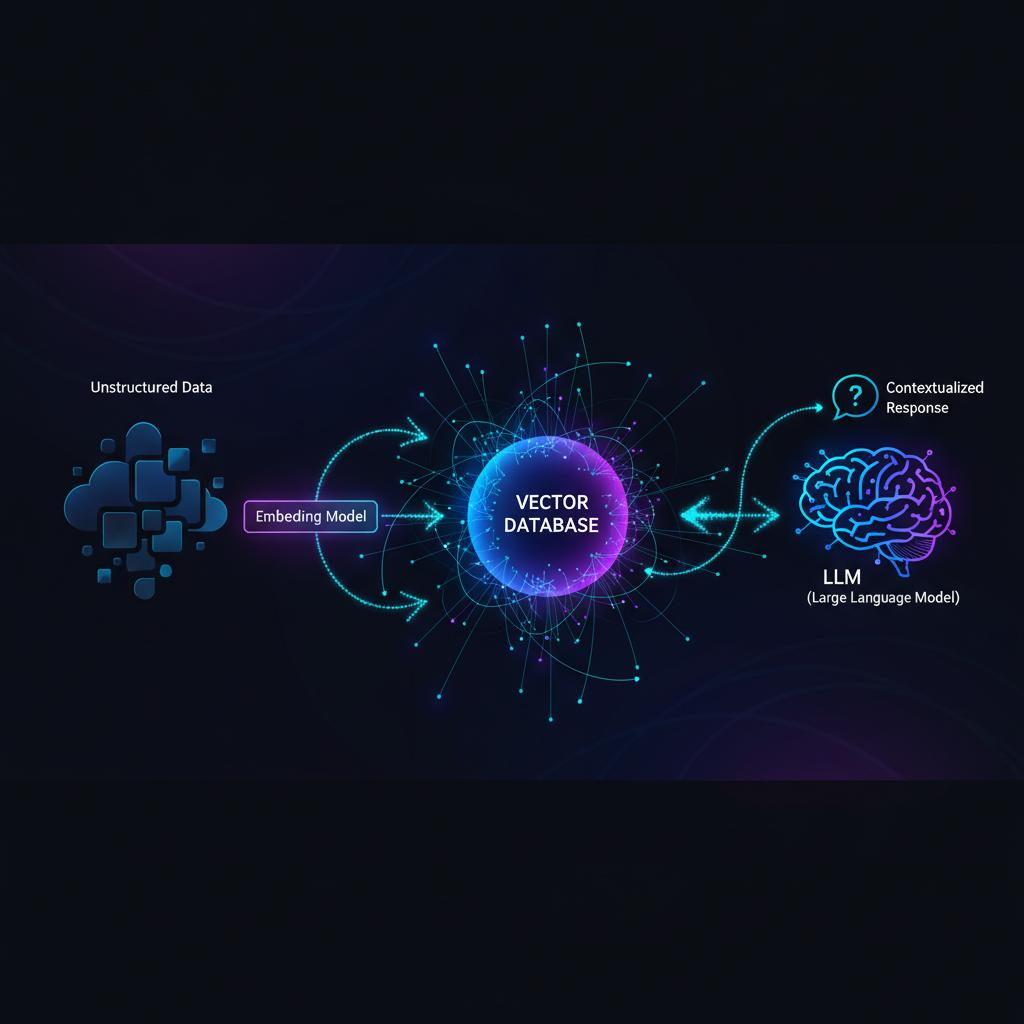
Antes de falar sobre os bancos de dados, precisamos entender seu conteúdo principal: os embeddings. Um embedding é uma representação vetorial de alta dimensão de um dado (texto, imagem, áudio). Modelos de linguagem especializados (como os da OpenAI, Cohere ou modelos open-source como BGE) transformam o texto em uma longa lista de números decimais (o vetor). A mágica reside no fato de que vetores próximos no espaço multidimensional representam dados semanticamente similares.
A Matemática por Trás da Similaridade
A medição de quão 'próximos' dois vetores estão é realizada através de métricas de distância. As mais comuns incluem:
- Distância Cosseno (Cosine Similarity): Mede o ângulo entre os vetores. É a métrica mais utilizada para texto, pois foca na direção do vetor, ignorando ligeiras variações de magnitude.
- Distância Euclidiana (L2): A distância 'em linha reta' entre os pontos no espaço vetorial.
- Produto Interno (Dot Product): Usado quando a magnitude do vetor é importante, mas geralmente menos comum que a cosseno na busca semântica pura.
A precisão da sua aplicação de IA depende diretamente da qualidade do modelo de embedding que você escolhe. Uma dica de insider: frequentemente, modelos específicos para um nicho (ex: biomedicina ou jurídico) superarão LLMs generalistas em tarefas específicas, mesmo que seus vetores tenham dimensões menores.
O Ciclo de Vida dos Dados Vetoriais
O processo envolve três etapas críticas:
- Geração: O texto bruto é passado por um modelo de embedding para gerar o vetor numérico.
- Indexação: O vetor, juntamente com metadados e o ID do documento original, é inserido no Vector Database.
- Busca: A consulta do usuário é transformada em um vetor (query vector), e o banco de dados encontra os vetores mais próximos (vizinhos mais próximos) usando algoritmos de aproximação (como HNSW).
Por Que Bancos de Dados Tradicionais Falham na Busca Semântica?
Bancos de dados relacionais (SQL) ou mesmo NoSQL focados em chave/valor são otimizados para consultas exatas ou baseadas em índices B-tree. Eles são terrivelmente ineficientes para comparar vetores de alta dimensão.
A Ineficiência da Força Bruta
Se tentássemos implementar busca vetorial em um PostgreSQL comum, teríamos que calcular a distância cosseno entre o vetor da consulta e todos os vetores armazenados (busca de força bruta). Para um catálogo com milhões de itens, este cálculo torna-se impraticável, levando segundos ou minutos por requisição. Em ambientes de produção onde a latência é medida em milissegundos, isso é um fator de falha imediato.
A Solução: Algoritmos de Vizinho Mais Próximo Aproximado (ANN)
Os bancos de dados vetoriais utilizam algoritmos ANN (Approximate Nearest Neighbor) para otimizar a busca. O mais popular hoje é o HNSW (Hierarchical Navigable Small World). Ele constrói um grafo multinível que permite que a busca navegue rapidamente até os vizinhos mais próximos, sacrificando uma pequena margem de precisão (aproximação) em troca de velocidade extrema. Já ajudei clientes que precisavam de respostas em menos de 50ms; sem HNSW ou técnicas similares, isso é impossível.
| Tipo de Banco | Otimização Principal | Latência Típica (Grande Escala) | Busca Semântica |
|---|---|---|---|
| Relacional (PostgreSQL) | Índices B-Tree, Consultas Exatas | Alta (segundos) | Ruim (requer força bruta) |
| Busca Texto (Elastic) | TF-IDF, BM25 | Média (100-300ms) | Aceitável (baseado em palavras-chave) |
| Vector Database | ANN (HNSW), Similaridade de Vetores | Baixa (< 50ms) | Excelente (baseado em significado) |
Principais Players no Ecossistema de Vector Databases
A escolha do banco de dados vetorial depende muito da sua necessidade de escalabilidade, custo e ecossistema. A Host You Secure frequentemente aconselha clientes na escolha entre soluções gerenciadas e auto-hospedadas.
Pinecone: O Serviço Gerenciado Líder
Pinecone é frequentemente a escolha inicial para muitas startups e empresas que buscam escalabilidade rápida sem a dor de cabeça de gerenciar a infraestrutura. Ele é puramente um serviço gerenciado (SaaS).
Vantagens e Desvantagens do Pinecone
- Vantagem: Facilidade de uso e escalabilidade horizontal automática. Você foca na ingestão de dados, e eles cuidam da otimização do índice HNSW em múltiplas instâncias.
- Desvantagem: Custo. Para grandes volumes de dados, o custo pode se tornar significativamente maior do que uma solução auto-hospedada em uma VPS otimizada.
Se você busca performance e controle total sobre sua infraestrutura de IA, migrar o armazenamento de dados para um servidor dedicado pode reduzir custos operacionais drasticamente. Considere nossas opções de VPS otimizadas para IA para hospedar soluções como ChromaDB ou Weaviate.
Weaviate: Open Source com Recursos Avançados
Weaviate é um banco de dados vetorial open source que se destaca por sua capacidade de funcionar como um banco de dados híbrido. Ele suporta busca vetorial nativamente, mas também permite indexação e query de metadados complexos (filtro booleano) de forma muito eficiente.
Em minha vivência, clientes que precisam de RAG com filtros complexos (ex: "Encontre documentos parecidos com este, mas apenas aqueles escritos após 2023 e taggeados como 'Financeiro'") encontram em Weaviate um excelente equilíbrio entre performance vetorial e capacidade de filtragem relacional.
ChromaDB: O Favorito dos Protótipos e Projetos Locais
ChromaDB ganhou muita popularidade por ser extremamente fácil de começar. Ele pode rodar em modo local (embedded) ou cliente/servidor. Sua simplicidade o torna perfeito para provas de conceito e desenvolvimento rápido.
O erro comum aqui é manter o ChromaDB em modo embedded para produção em larga escala. Embora ele suporte o modo servidor, para centenas de milhões de vetores, soluções mais robustas em termos de clusterização (como Pinecone ou Weaviate em Kubernetes) são preferíveis. Utilize ChromaDB para prototipagem rápida e transição para outro sistema ao validar a arquitetura.
Aplicação Prática: O Padrão RAG (Retrieval-Augmented Generation)
A aplicação mais impactante dos bancos de dados vetoriais hoje é na arquitetura RAG. RAG resolve o problema fundamental de LLMs: o conhecimento estático e a alucinação (inventar fatos).
Como Funciona o RAG com Vector Databases
O RAG integra a capacidade de busca do Vector Database com a capacidade generativa do LLM:
- Consulta: O usuário pergunta: "Qual foi a política de férias alterada em 2024?"
- Embedding da Consulta: A pergunta é transformada em um vetor.
- Busca Vetorial: O Vector Database busca os documentos mais semanticamente similares no seu índice interno (ex: documentos sobre RH, políticas internas, etc.). Estes são os contextos recuperados.
- Geração Aumentada: O prompt enviado ao LLM (como GPT-4 ou Llama) é reescrito para incluir o contexto: "Usando o texto a seguir como base, responda: [Contexto Recuperado]. Pergunta: Qual foi a política de férias alterada em 2024?"
- Resposta: O LLM gera uma resposta precisa, baseada nos seus dados privados, citando fontes internas.
Na minha experiência ajudando empresas de consultoria, implementar RAG corretamente, com boa separação e indexação dos embeddings, garante que o custo por chamada da API do LLM seja mais baixo (pois o prompt de contexto é menor) e a taxa de acerto factual seja drasticamente maior.
Dica de Insider: Chunking Inteligente
Um erro comum é o chunking (divisão do documento em pedaços para indexação) ser muito genérico. Se seus chunks forem muito curtos, você perde contexto; se forem muito longos, você polui o embedding com ruído e desperdiça tokens no LLM.
A abordagem que recomendo é o Overlapping Chunking, onde cada pedaço de texto de 500 tokens possui uma sobreposição de 50-100 tokens com o pedaço anterior e posterior. Isso garante que transições contextuais críticas entre os documentos não sejam cortadas, melhorando a qualidade da recuperação.
Desafios e Manutenção de Bancos de Dados Vetoriais
Apesar do poder, a gestão de bancos vetoriais introduz desafios específicos de infraestrutura, algo que abordamos diariamente na Host You Secure.
Escalabilidade e Latência na Indexação
Indexar milhões de vetores de alta dimensão (ex: 1536 dimensões para OpenAI Ada) consome muita CPU e memória. O índice HNSW, embora rápido para busca, é caro para construir e atualizar. Você precisa de hardware robusto para lidar com a ingestão contínua de dados sem degradar a performance de consulta.
Se você estiver auto-hospedando Weaviate ou outro serviço, garanta que seu VPS ou servidor dedicado tenha memória RAM suficiente, pois os índices vetoriais (especialmente HNSW) são frequentemente mantidos integralmente na memória para a velocidade máxima.
Manutenção e Drift Semântico
O drift semântico é um problema sutil. Com o tempo, novos modelos de embedding são lançados (ex: um novo modelo da OpenAI ou Hugging Face). Se você migrar seu sistema para usar um modelo novo, todos os seus vetores antigos se tornarão obsoletos, pois foram gerados com a matemática do modelo anterior.
Para evitar isso, você deve planejar ciclos de reindexação ou usar um modelo de embedding estável por longos períodos. É um fator de custo operacional que muitos ignoram no planejamento inicial.
Conclusão e Próximos Passos
Bancos de dados vetoriais como Pinecone, Weaviate e ChromaDB não são apenas mais uma opção de banco de dados; eles são a fundação para a próxima geração de busca, recomendação e IA conversacional baseada em RAG. Eles habilitam a inteligência contextual necessária para mover as aplicações além da mera correspondência de palavras-chave.
Se você está iniciando um projeto de IA, comece pequeno com ChromaDB para prototipar seus embeddings, mas planeje a migração para uma solução escalável. A complexidade da indexação vetorial exige expertise em infraestrutura. Precisa de ajuda para projetar uma arquitetura de IA escalável e resiliente em nuvem ou em servidores dedicados? Fale com a Host You Secure hoje mesmo e garanta que sua infraestrutura suporte o poder da busca semântica!
Leia também: Veja mais tutoriais de N8N
Comentários (0)
Ainda não há comentários. Seja o primeiro!